
Особенности разгона оперативной памяти на процессорах Zen 2
Интересной информацией, которая не попала в Сеть, является измененный рабочий procODT (на любой материнской плате), теперь оптимальный диапазон находится в переделах 28–36,9 Ом для одноранговой памяти и 36,9–53,3 Ом для двуранговой. Подобные изменения очень сильно повлияли на разгон, и теперь пользователи могут получить до 4600 МГц включительно на большинстве топ-плат. Рабочие RTT остались теми же что и были. RTT_NOM предлагаю оставить в Disabled, если у вас в системе два модуля (четыре для HEDT) и RZQ/7 (34 Ом) для конфигураций с четырьмя модулями (восемь для HEDT).
RTT_WR в режиме RZQ/3 (80 Ом) или RZQ/2 (120 Ом) + RTT_PARK в режиме RZQ/1 (240 Ом) рекомендую использоваться только для двуранговой памяти или четырех одноранговых модулей для AM4 или восьми одноранговых планок для HEDT. В остальных случаях RTT_WR Dynamic ODT off + RTT_PARK RZQ/5 (48 Ом)
Некоторых изменений претерпел и CAD_BUS, теперь самыми оптимальными значениями являются 24 20 20 24 вместо стандартных 24 24 24 24. В большинстве случаев эта настройка позволяет существенно улучшить стабильность системы. Также увеличение значения CAD_BUS ClkDrvStren до 30 или 40 (или даже 60) положительно повлияет на стабильность системы, в которой отключен GearDown Mode или установлены 4/8 модулей ОЗУ. Значение 120 будет полезно для отключения GDM в системах, где используются двухранговые модули. Хочу отметить, что это не является рекомендацией AMD, а моя, и есть большая надежда, что подобные правила разгона будут внесены в следующие AGESA.
Также Zen 2 представил новую настройку напряжения, которая называется CLDO_VDDG. CLDO в названии означает, что в напряжении используется стабилизатор выпадения (LDO = низкий уровень выпадения). VDDG — это напряжение IF (Infinity Fabric), как могли догадаться, отвечает за целостность данных, курсирующих через IF. Существует для стабилизации высоких частот FCLK. В последних AGESA было разделено CLDO_VDDG на две настройки: VDDG CCD и VDDG IOD. Первая отвечает за IF между CCX, а второй параметр отвечает за дальнобойный линк IF между IOD и CCD.
Так как CLDO_VDDG и CLDO_VDDP регулируются из плоскости VDDCR_SoC, существует правило установки VDDG. Напряжение SoC должно быть выше, чем запрошенный VDDG. По умолчанию оно составляет 0,950 В, однако некоторые материнские платы могут превышать уровень по умолчанию даже при стандартных настройках и даже быть причиной отсутствия загрузки системы из-за завышенного напряжения.
Моя рекомендация использовать ручное VDDG со значением 0,95 В (хватает для разгона FCLK до 1800 МГц включительно) или же держать интервал 0,05 В между ним и SoC, в противном случае система не будет использовать пользовательские настройки VDDG. Безопасный предел для VDDG до 1,1 В включительно.
CLDO_VDDP советую вообще не трогать, 0,9 вольт замечательное число, которое позволяет тренировать память на частотах 2133–4333 МГц. «Memory Holes» на моих экземплярах обнаружено не было.
Сниженного аппетита к напряжению DRAM я не заметил. Тайминги зажимаются аналогично, без каких-либо сюрпризов, потому вы можете использовать с легкостью конфигурации с прошлого Ryzen.
Насчет режимов 2:1 и 1:1 (MEMCLK:UCLK). Переключение между ними автоматическое, после того как память достигла 3600 МГц идет автоматический переход в режим 2:1, но так как присутствует запас по частоте UCLK/FCLK 1900 МГц режим 1:1 можно вернуть, выставив в FCLK значение, равное половине от эффективной частоты оперативной памяти. Из особенностей это «колдбут» при переходе в режим 2:1 или 1:1, он будет всегда, так как режимы задействуют либо один тактовый генератор процессора, либо тактовый генератор процессора и материнской платы сразу (не у всех материнских плат стоит внешний тактовый генератор BCLK, не стоит скидывать со счетов и это). Второй нюанс — POST-код на материнской плате «07» означает, что лимит FCLK достигнут по той или иной причине и зачастую наваливание напряжения на VDDG просто не даст никакого результата. В частности, высокое напряжение на VDDG_CCD будет полезно при использовании LN2.
Разгон FCLK ограничен заводcким бином чипов IOD, 1866–1900 МГц — это максимум, который может получить большинство пользователей, хотя встречались пару образцов, способные достигнуть 1966 МГц. С BCLK я смог найти критическую точку, когда система перестает загружаться даже если существенно завышать SOC или VDDG. Это 1889 МГц для моего экземпляра AMD Ryzen Threadripper 3690Х. Я также сталкивался с ситуацией, в которой экземпляр Ryzen 7 3700X не имел стабильности даже на 1866 МГц. Возникала проблема в играх, в виде мерцания экрана. Изменение напряжений на VDDG CCD и VDDG IOD ситуацию не изменило.
Если говорить о моем экземпляре IOD, он оказался с отличным бином, частота 3733 МГц для восьми модулей покорилась легко на ASUS ROG Zenith II Extreme при SOC 1,025 В и 0,95 В VDDG. Тем не менее 3800 МГц были бездыханными.
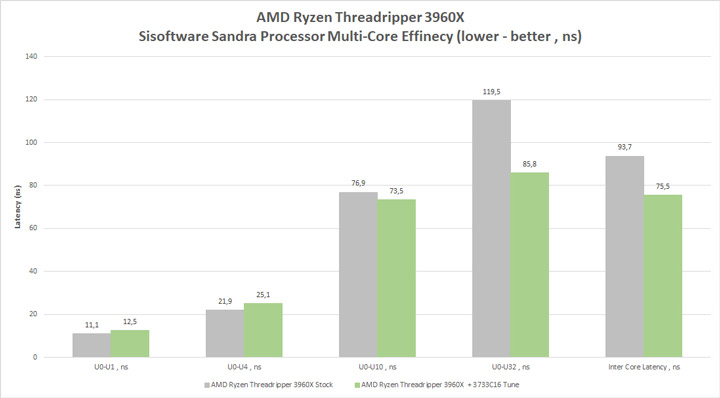
–39% по задержке между самыми дальними CCD — это еще одна причина, по которой вам стоит заняться разгоном/оптимизацией системы. Кстати, обратите внимание, что при разгоне FCLK в случае Ryzen Threadripper 3690Х пропускная способность не увеличилась, а продемонстрировала отрицательный эффект.
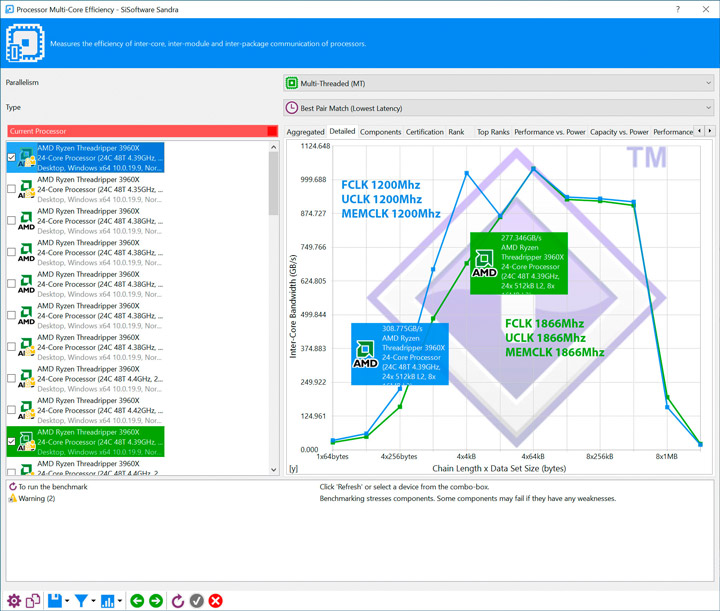
Подобное явление может говорить только о том, что AMD использует троттлинг для Infinity Fabric. К примеру, каждый 10-й или 20-й такт или даже серия тактов являются холостыми, при которых не происходит прием или передача информации. Возможно это способ дождаться затухания шумов/переотражений на дальнобойных линках, а возможно это искусственное ограничение, снятие которого будет представлено в Zen 3 как новшество, в котором рост пропускной способности интерконекта позволит увеличить производительность процессора. Тем не менее, на данный момент мы имеем серьезные просадки для мелкоблочных операций и это безусловно сказывается на итоговой производительности процессора.
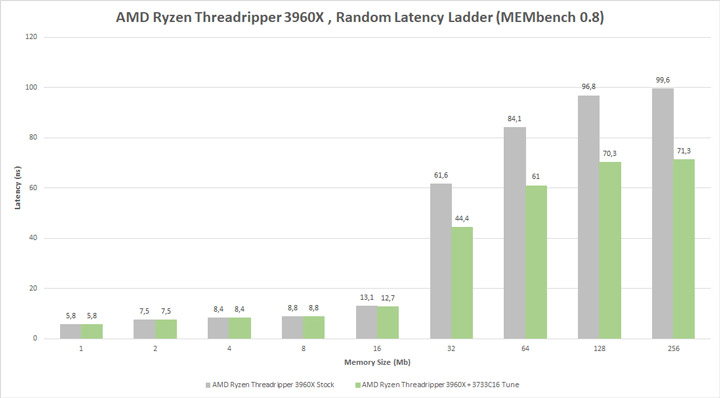
Также разгон FCLK положительно влияет на время доступа к кэшу L3. Несущественным минусом архитектуры Zen 2 является кэш-память третьего уровня, которая не является монолитной структурой с процессорными ядрами. Доступ ядра CCX1 к кэш-памяти L3 CCX2 имеет дополнительную задержку из-за задержки доступа к Infinity Fabric. Не забывайте, что ядро с CCX1 может даже получить доступ к L3 CCX8, в этом случае время доступа к кэшу третьего уровня немного меньше времени доступа к DRAM. К счастью, в Zen 3 пользователи получат CCX на 8 ядрах и монолитный кэш L3, что, безусловно, повлияет на конечную производительность.
Что касается урезанной полосы пропускания записи между CCD и IOD (для записи 16 байтов за такт и 32 байта за такт для чтения), я не увидел существенного недостатка, даже в приложениях, которые требуют высокой пропускной способности записи в ОЗУ, они могут незначительно потерять производительность. В играх подобной ситуации не наблюдается, так как скорость записи на самом деле не важна. В любом случае, x86 имеет соотношение чтения / записи 2:1, и многие новые инструкции имеют даже соотношение 3:1.
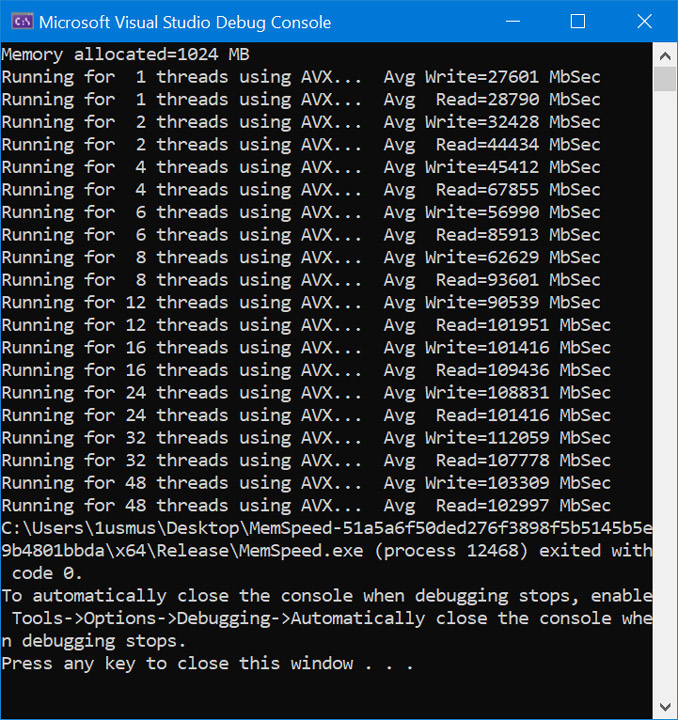
Безусловно любопытным тестом является замер пропускной способности чтения и записи оперативной памяти для разного количества потоков. По результатам вы можете заметить, что один поток не имеет доступ сразу к двум каналам, хотя в этом нет ничего особенного, все решения Intel в этом плане аналогичны.
Последним интересным параметром является PMU Pattern Bits, опция, которая может повлиять на тренировку памяти и стабильность системы в целом. Рекомендуемые значения 6–10. И чем больше значение, тем эффективнее будет работать система тренинга. Соответственно, это займет дополнительное время при каждом запуске системы.
А как обстоят дела с восьмью рангами на четырех каналах? В большинстве тестовые пакеты никак не отреагировали на удвоение количества объёма памяти и ранг, единственный пакет, где было замечено преимущество, это компиляция игрового движка UE4, но этот результат скорее всего обусловлен тем, что меньше было задействовано файла подкачки.