
Компания OpenAI, ведущий разработчик в сфере искусственного интеллекта, выпустила специальный тест SimpleQA, который позволяет оценить точность выходных данных для современных моделей ИИ. Это тест фактологии, который измеряет способность языковых моделей отвечать на короткие вопросы, требующие поиска фактов. И внезапно он показал чрезвычайно низкие результаты даже для самых лучших языковых моделей LLM.

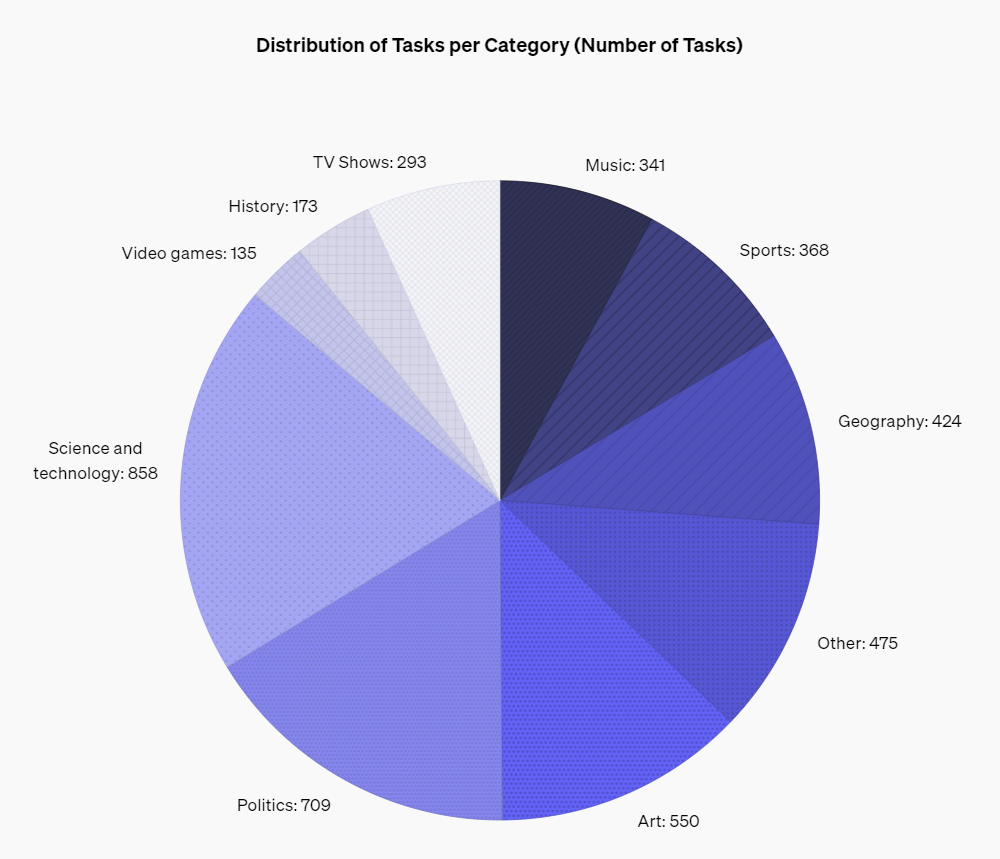
Точность данных выдачи ИИ является известной проблемой. И важно было бы иметь инструмент, который мог оценить корректность информации и помочь выявить, какая из моделей ИИ демонстрирует меньше «галлюцинаций». Для этого и создавался бенчмарк SimpleQA. Он охватывает широкий спектр тем — от науки и технологий до телешоу и видеоигр.
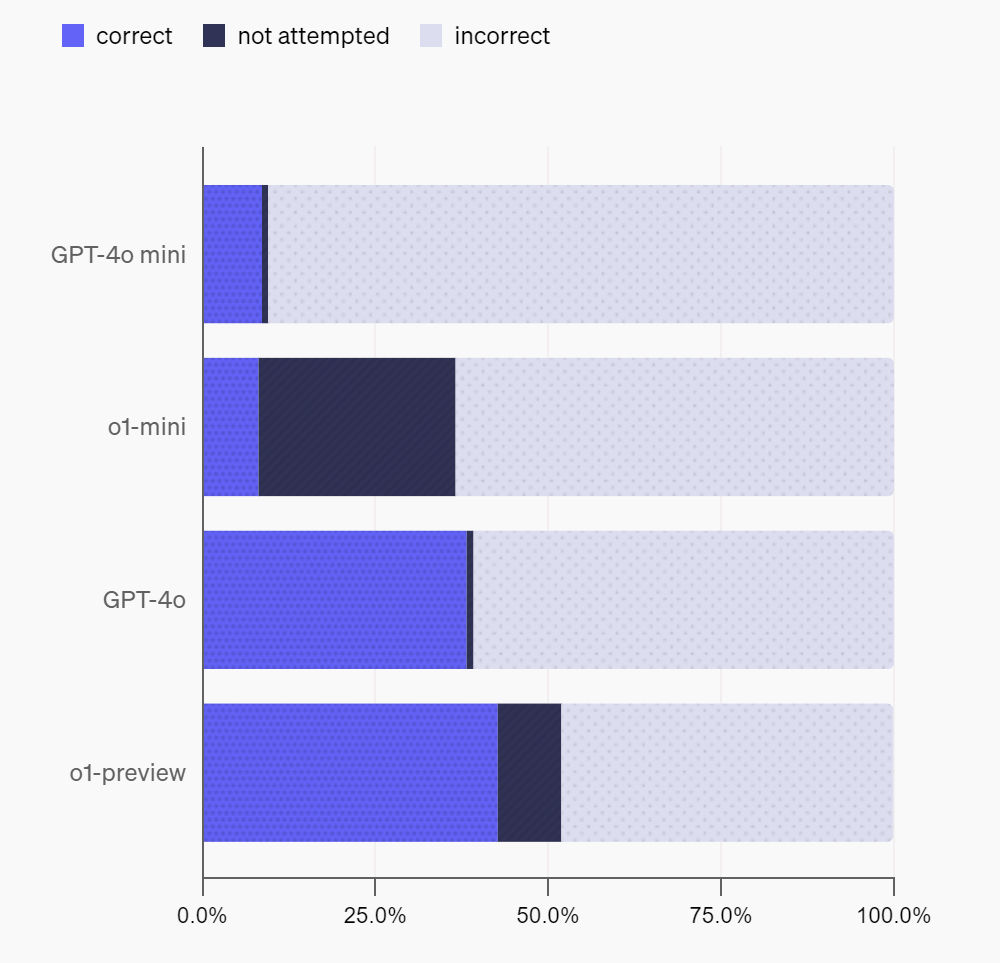
Первые испытания в этом тесте показали неутешительные результаты для современных моделей ИИ. Даже o1-preview и GPT-4o выдают менее половины корректных ответов. Самой точной оказалась модель o1 с 42,7% точных ответов. И это на самом деле неплохо, поскольку конкурирующие ИИ Anthropic и Claude-3.5-sonnet дали еще худшие результаты. Малые модели GPT-4o mini и o1-mini выдают менее 10% точных ответов, что ожидаемо, ведь они обладают меньшим количеством данных о внешнем мире.
Данные для теста выбирались с помощью многоуровневой системы тренеров ИИ. Одна категория тренеров просматривала веб-страницы и создавала короткие вопросы для поиска фактов и ответов. Чтобы попасть в набор данных, вопрос должен был соответствовать определенным критериям, в том числе иметь один бесспорный ответ, который не меняется со временем. Но также большинство вопросов выбирались с учетом того, что они должны вызвать галлюцинации GPT-4o или GPT-3.5. Для повышения качества набора данных потом независимый тренер ИИ отвечал на каждый вопрос, не зная готового ответа. В итоговую подборку пошли вопросы, где совпадали ответы обоих тренеров ИИ. Потом использовался третий тренер, который отвечал на случайную выборку вопросов. И в конце набор данных проходил дополнительный ручной контроль, который показал внутреннюю погрешность точности на уровне 3%.
В целом это сложный тест, который призван испытать точность ИИ. Он может использоваться для калибровки ИИ, поскольку на один и тот же вопрос ИИ могут выдавать разные данные при повторных обращениях. Но в целом есть тенденция к тому, что модели завышают свою уверенность в ответах. Это требует дополнительных исследований и разработки. А инструмент OpenAI SimpleQA с открытым исходным поможет в этом.