
Будова CCD та ієрархія кешів
Ієрархія кешів має невеликі зміни.
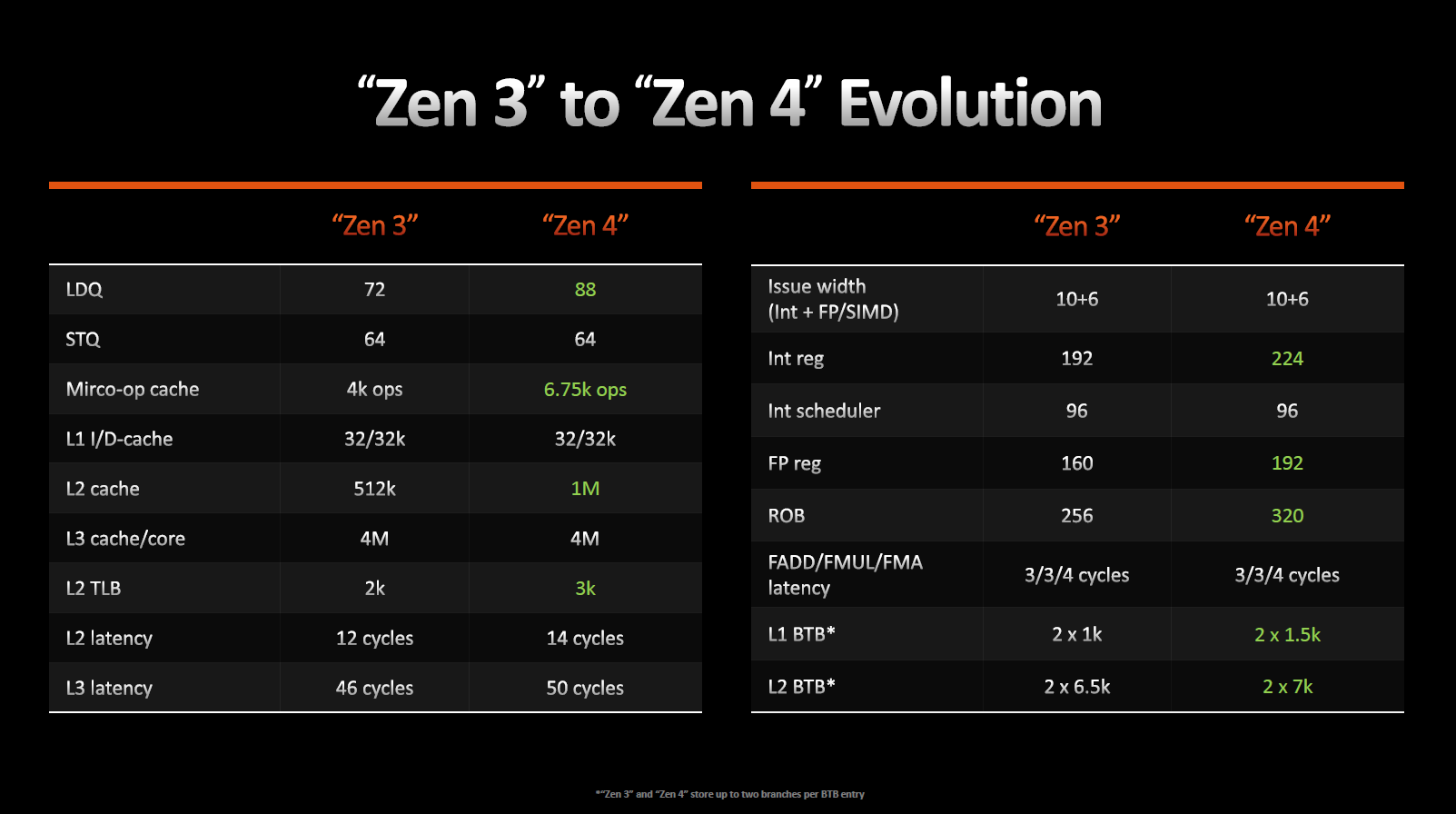
Кеш-пам'ять L1-I та L1-D, як і раніше, має 32 Кбайт з 8-канальною асоціативністю, а кеш-пам'ять другого рівня став 1024 Кбайт з 8-канальною асоціативністю, що вдвічі більше, ніж у попередника. З погляду транзисторного бюджету незрівнянне підвищення витрат щодо отриманого приросту IPC на 1%, але це виправдовує себе на високоінтенсивних навантаженнях, зокрема у серверному сегменті.
Zen 4 підтримує 64 суттєвих пропусків між L2 і L3 на ядро і 224 між L3 та оперативною пам'яттю.
Кеш інструкцій (L1-I) на цикл може забезпечувати 32-байтову вибірку, в той час, як кеш даних (L1-D) допускає три 32-байтових завантаження і два 32-байтових збереження за цикл. Черга на збереження не змінилася, але черга на завантаження зросла з 72 до 88. Буфер трансляції адрес (TLB) L2-кешу також виріс на 50% і тепер становить 3 Кбайт.
Варто зазначити, що подібні зміни мають серйозно вплинути на продуктивність у високоінтенсивних завданнях, які призводять до більшої кількості завантажень, ніж збереження.
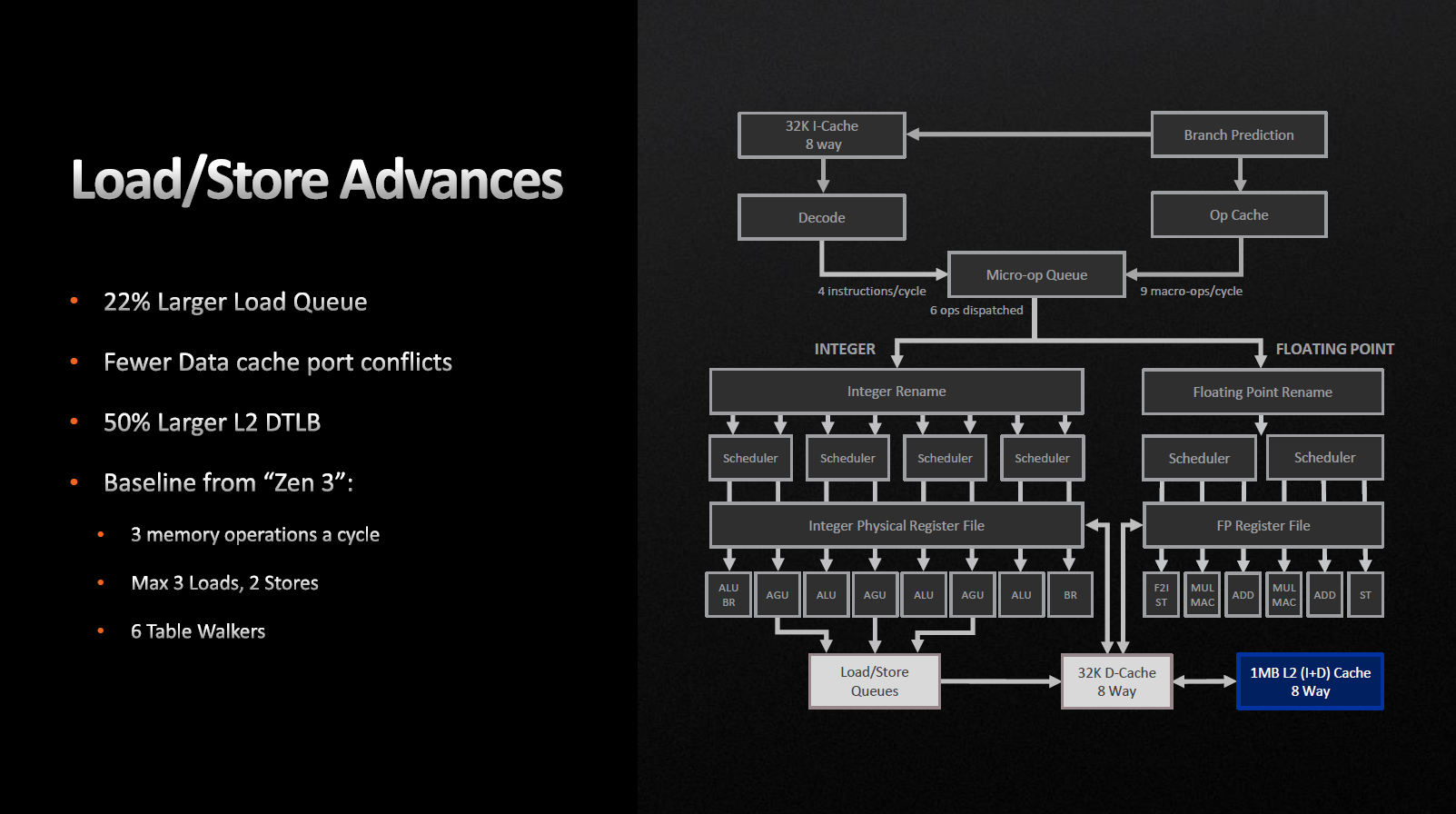
Доступ прилеглих ядер до кешу L3 здійснюється без використання Infinity Fabric, тут змін немає. Затримка L3-кешу збільшилася з 46 до 50 тактів. Основною причиною цього явища так само є обсяг монолітної структури та зрослі тактові частоти L3. Механізм заповнення кешу третього рівня — віктимний, тобто на нього не поширюється попередня вибірка, дані просто витісняються до нього з L2. Таким чином, L3-кеш виявляється переважно ексклюзивним.
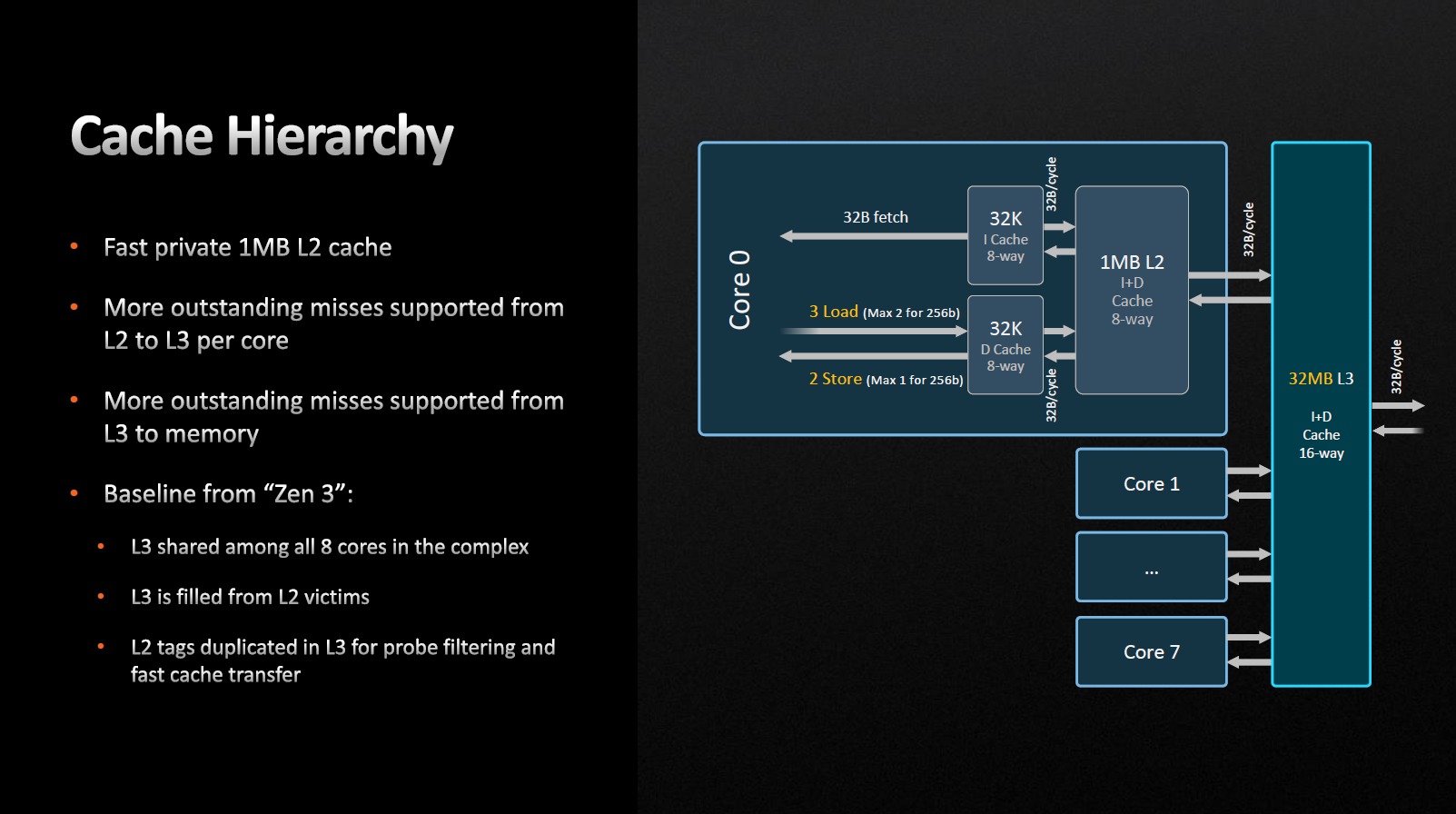
Компанія AMD заявляє, що кількість промахів кешів L2 до L3 та L3 до оперативної пам'яті зросла. Тобто якщо результат запиту, що обробляється, відсутній в кеші, і щоб його отримати необхідно звертатися до зовнішньої пам'яті. При отриманні відповіді ми можемо зберегти нове значення в кеш, витіснивши деяке старе, як результат — збільшення швидкодії.
Виконавчий блок та провісник розгалужень
Виконавчий блок майже не змінився. Так само ми маємо чотири цілочисельних уніфікованих планувальників та двох планувальників дійсних значень. Реєстровий файл загального призначення зріс зі 192 до 224, а регістровий файл для дійсних значень зріс зі 160 до 192 записів.
«Ширина» конвеєра залишилася незмінною, він дозволяє виконувати за один цикл 10 цілочисельних та шість мікрооперацій з дійсними числами.
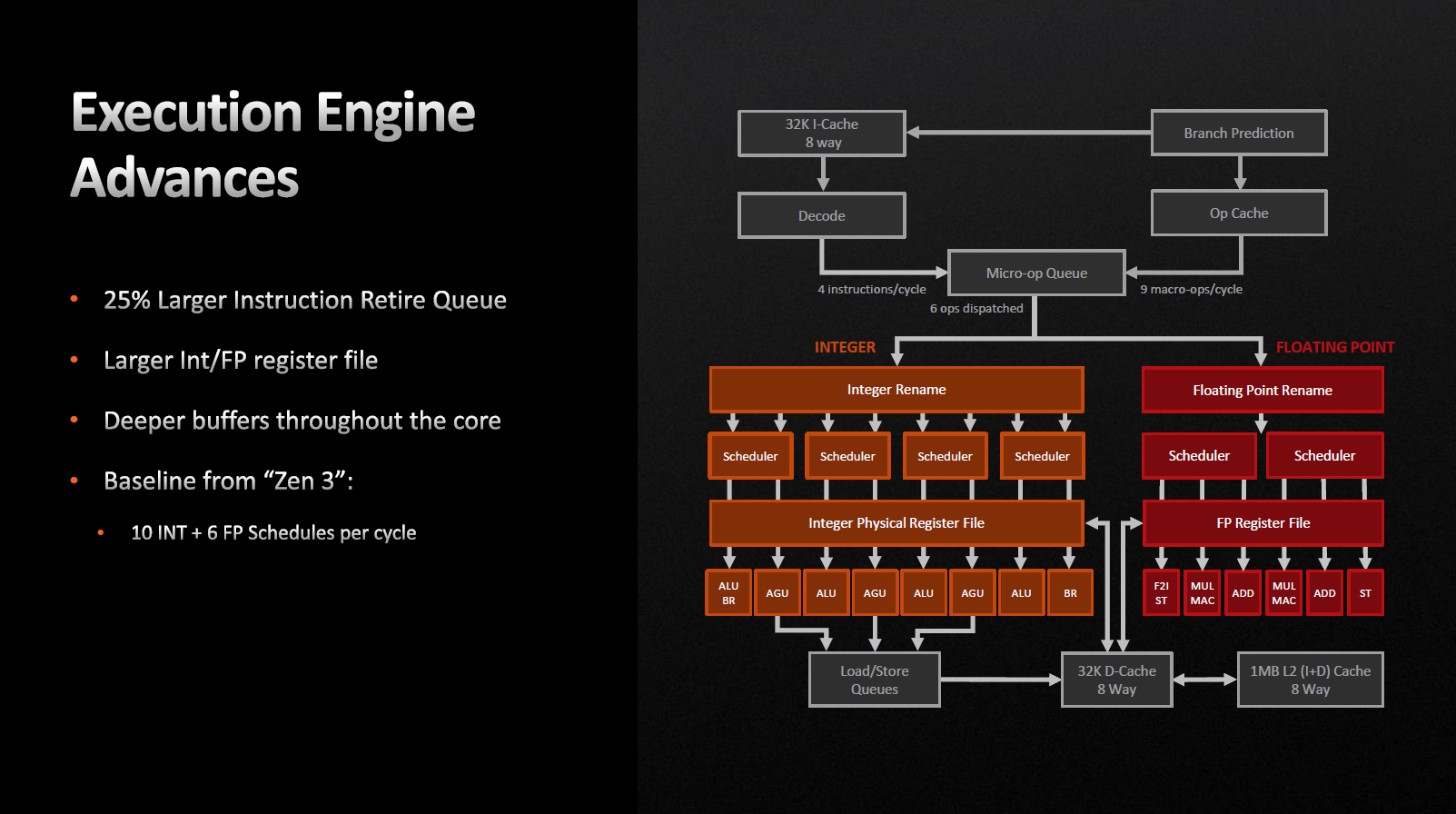
Зазначається, що буфери по всьому ядру стали глибшими, а черга команд на вибуття зросла на 25%.
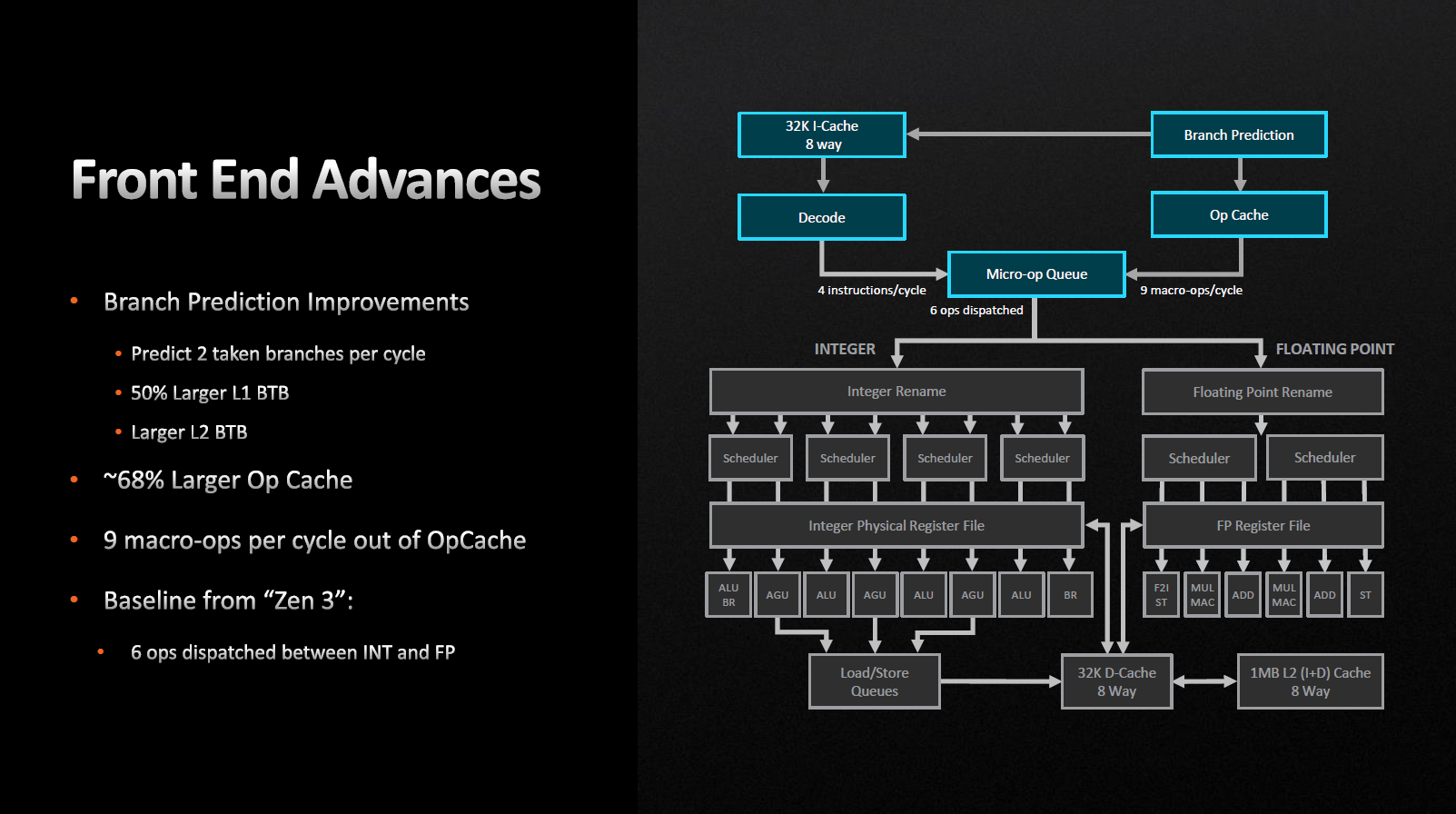
Архітектура Zen 4 дозволяє провіснику розгалужень за один цикл обробляти відразу дві «гілки» замість однієї, як було раніше. Принагідно були збільшені цільові буфери розгалуження (BTB) для кешів L1 і L2. Мікроопераційний кеш був також збільшений з 4 до 6,75 Кбайт. Як результат, ми можемо спостерігати збільшення кількості вихідних мікрооперацій з операційного кешу з восьми до дев'яти за один цикл.
Хочу зазначити, що всі вищезгадані зміни насамперед спрямовані на те, щоб конвеєр був максимально завантажений і не виникало ситуацій із «простоєм». Так, безумовно хотілося побачити «ширший» конвеєр і «жирніший» декодер інструкцій, але це припасовано для майбутніх архітектур.
AVX-512 та прискорення обчислень для нейромереж
Якось «батько» сімейства операційних систем Linux Лінус Торвальдс критично висловився про перспективи розширення набору команд Intel AVX-512 (Advanced Vector Extensions). Основним посилом було те, що на той момент Intel марно палила транзисторний бюджет, створюючи магічні інструкції, придатні тільки для тестів і порівняльної переваги над конкурентами. Закінчилося це тим, що Intel почала блокувати AVX-512 через виробників материнських плат. Тепер із цим прийшла компанія AMD. Чому?
Як і всі попередники, AVX-512 призначений прискорити роботу додатків, які використовують мультимедійні інструкції до роботи певних алгоритмів. Наприклад, AVX та AVX2 використовуються для прискорення конвертації відео, емуляторів ігрових приставок, роботи фото- та відеоредакторів, зокрема для розмиття фону та інших операцій.

Помітного прискорення коштом нових інструкцій вже сьогодні можна досягти й при кодуванні відео формату HEVC. Представники AMD говорять про те, що ці інструкції в першу чергу стануть у пригоді для програмного забезпечення, яке залучає глибинне навчання та штучний інтелект, а також різні техніки масштабування зображень.
Друга причина поточного приходу AVX-512 у настільний сегмент — це те, що серверна архітектура є батьком настільних процесорів. Саме в серверній архітектурі AVX-512 досить ефективно використовується для наукових розрахунків, моделювання та інших високоінтенсивних задач. По суті те, що ми маємо, це приємний бонус, на якому робиться акцент.
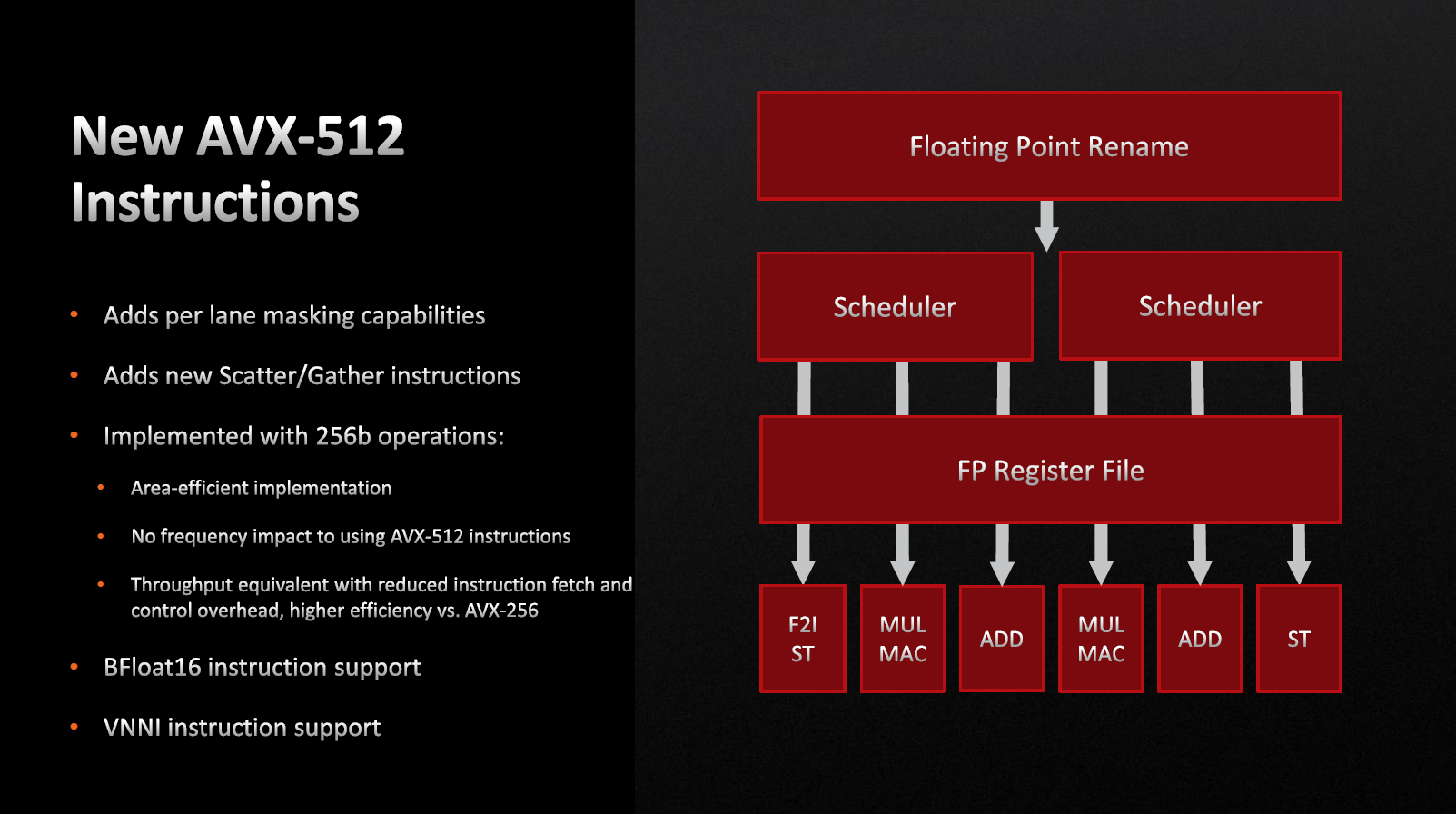
Потрібно віддати належне, штрафів виконання AVX-512 немає, а частотний ліміт обмежений лише допусками струму та температури.