
Платформа AM4 стала напевно найуспішнішою за всю історію компанії AMD. П'ять років користувачі могли не змінювати материнську плату і постійно залишатися в строю, насолоджуючись щорічним оновленням архітектури Zen. Ні, це не просто три літери, це покоління процесорних архітектур, які буквально змусили «ворушитися» весь кремнієвий ринок. Архітектура Zen перша підкорювала нові технологічні норми виробництва і перша вразила світ кількістю ядер для настільного сегмента.

Ми побачили нарешті гідну конкуренцію продуктам синього гіганта та серйозне зростання IPC. Тепер ми є свідками нової епохи, яка ховається під кодовим словом AM5. Саме вона покликана продовжити шлях архітектури Zen і найближчим часом знову здивувати користувачів не лише кількістю ядер, а й подоланням психологічного рубежу в 5 ГГц для багатопотокових завдань. Погодьтеся, інтригує.
Платформа AM5
Нерідко з виходом нових платформ у користувачів виникає питання «а навіщо міняти сокет чи чипсет?», якщо, здавалося б, ми й так маємо вже досить потужні підсистеми живлення, якісне трасування сигнальних ліній та достатній обсяг пам'яті для UEFI. Розбираймось послідовно на прикладі AM5.

У 2022 році перегони технологій енергоефективності досягли свого апогею, метою яких є досягнення максимальної продуктивності та адаптивність щодо типу навантаження. За ширмою цих красивих слів знаходиться простіше поняття — розумна зміна частоти відносно напруги та навантаження. Крім процесора левову частку відповідальності за це несе і материнська плата, яка повинна забезпечувати запитуване живлення з належним відгуком. Крім відгуку важливим елементом є точність даних, одержуваних з різних датчиків, які контролюють стан «здоров'я» процесора та надають йому більш точну інформацію щодо поточних можливостей різних регуляторів VRM.

AM5 отримала новий високошвидкісний стандарт AMD Serial Voltage 3 (SVI3), раніше представлений у серії мобільних процесорів Ryzen 6000. SVI3 забезпечує більш точне керування живленням, покращений контроль телеметрії та значно швидшу реакцію на зміну напруги. Зокрема, для настільних рішень SVI3 також підтримує більшу кількість фаз живлення, що буде особливо корисним для high-end материнських плат X670E.
Наступним важливим новаторством є стандарт PCI Express 5.0. Однією з основних відмінностей між кожним поколінням PCIe є швидкість та пропускна спроможність. Говорячи мовою цифр, PCIe Gen 5.0 у конфігурації x16 має швидкість передачі до 32 ГТ/с і пропускну здатність до 128 ГБ/с, що вдвічі більше, ніж у стандарту PCIe 4.0.
Ще одна проблема, яку покликаний вирішити PCIe 5.0 — нестача живлення відеокарти. Правильно, PCIe 5.0 зможе забезпечити достатню потужність відеокарт класу high-end. PCI-SIG стверджує, що кожен контакт в основному блоці може підтримувати до 9,2 А. У сумі це становить 55,2 А для всього роз'єму з максимальною підтримуваною потужністю 662,4 Вт. З урахуванням допусків ви отримаєте 600 Вт (300 Вт для PCIe 4.0), чого цілком достатньо навіть для ненажерливої відеокарти, але з однією умовою — відеокарта теж повинна підтримувати стандарт PCIe 5.0.

Покращення продуктивності отримають і M.2 NVMe. Вже зараз досить багато анонсованих продуктів, які можуть подолати психологічну позначку швидкості читання в 10 ГБ/с.
Кількість процесорних ліній PCIe зросла з 24 до 28, для потреб відеокарт виділяється так само 16, а для NVMe — 8. Додаткові 4 лінії призначені для периферії та нових високошвидкісних 20 і 10 Гбіт/с USB-портів.

Ключові відмінності між чипсетами з суфіксом «E» та без полягають в обов'язковій підтримці процесорних ліній PCI Express 5.0 для «екстремального» чипсету. Цікаво, але судячи з вищенаведеної ілюстрації, компанія AMD вирішила не говорити про це. Проте наявність підтримки визначатимуть виробники материнських плат. Чипсет B650(E) припаде до душі користувачам, яким не потрібна така велика кількість портів та інтерфейсів, що своєю чергою дозволить суттєво заощадити гроші.

Також хочу зазначити, що тепер платформою AM5 підтримується виведення зображення через порти USB стандарту Type-C, кількість яких дорівнює трьом (!). Є і підтримка WiFI-E6 з DBS/Bluetooth Low Energy 5.2.
Завершує список унікальних нововведень підтримка високосортної пам'яті DDR5. Різниця між новою оперативною пам'яттю та її попередницею виявляється у подвоєній швидкості передачі даних. Нові модулі пам'яті припускають вдвічі більшу кількість груп банків (8 проти 4), причому кількість банків групи залишається колишнім і рівне чотирьом.

У результаті швидша шина даних буде заповнена швидше, при нагоді збільшуючи ефективність транзакцій, оскільки зростання кількості груп банків дозволяє залишати одночасно відкритим більшу кількість сторінок і тим самим збільшити ймовірність доступу до даних. Збільшення частоти інтерфейсу пам'яті забезпечується подвоєнням довжини пакетів. Якщо для DDR4 в один пакет входило вісім послідовних пересилань по шині даних, то у DDR5 їх стало 16.
Ширина шини в обох варіантах оперативної пам'яті однакова, 64 біт, DDR5 може похвалитися покращеною архітектурою каналів. Кожна планка оперативної пам'яті містить два канали, а не один як DDR4. Виграш від такого нововведення дозволяє виконувати дві різні операції одночасно з одного модуля. Також кожен суб-канал отримав свою 8-бітну шину ECC. Ця функція автоматичного виправлення помилок дозволяє системам, що використовують пам'ять DDR5, мати вищу стабільність та відсутність переривань через помилки.

Зростання продуктивності DDR5 щодо DDR4 так само обумовлене тим, що новинка навчилася «регенерувати» інформацію в комірках побанково, раніше ця операція проводилася для всіх банків відразу. Збереження даних в комірках вимагає регенерації заряду через певні проміжки часу. У DDR4 цей процес вимагав зупинення будь-яких інших операцій, що за фактом періодично блокувало будь-які корисні операції. У новій пам'яті регенерацію для різних банків у групах можна виконувати по черзі, причому інші банки залишаються доступними для звернень. Цей підхід збільшує продуктивність DDR5 на додаткові 6—9%.

Також у DDR5 управління живленням перенесене з материнської плати на сам модуль (DIMM). Модулі облаштовані 12-вольтовими ІС керування живленням (PMIC), що дозволить краще контролювати енергоспоживання системи. Також PMIC забезпечує покращену цілісність сигналу та нижчий рівень шуму.
Остання зміна — це те, що ви вже напевно знаєте, DDR5 має великий обсяг і модуль об'ємом 16 Гбайт стає рекомендованою стартовою відміткою для будь-якої системи.

Підбиваючи підсумок цього розділу хочеться відзначити, що нова архітектура процесора просто не могла бути реалізована на старій платформі, нововведень не просто багато, а дуже багато. Платформа AM5 вкотре має стати довгожителем, підтримка планується як мінімум до 2025 року. Приємним бонусом є підтримка систем охолодження із кріпленням AM4. Єдиним, мабуть, недоліком серед перерахованого буде ціна.
Архітектура Zen 4
Структурно Zen 4 не відрізняється від попередника: один або два комплекси, які називаються CCD, залежно від моделі. Кожен CCD складається з восьми повноцінних ядер та 32 МБ кешу L3, пов'язаних між собою кільцевою шиною. Транзисторний бюджет одного CCD містить 6,57 мільярда транзисторів, що на 58% більше, ніж у CCD архітектури Zen 3. Кількість ядер для флагманського рішення незмінно — 16 ядер із технологією SMT.

Основний акцент був зроблений на впровадження нових інструкцій AVX-512 та AVX-512 VNNI (прискорення обчислень для нейромереж), збільшення буфера розгалуження (BTB) та розмірі Op-кешу, удосконаленні провісника розгалужень, збільшенні розмірів файлових регістрів, збільшенні черги команд та низці інших змін, щоб конвеєр максимально ефективно справлявся з новими інструкціями. Зрозуміло, дані архітектурні покращення суттєво вплинули й на арифметичні здібності процесора, навіть без використання AVX-512, але про це у наступних розділах.
Заявлений приріст виконуваних інструкцій за такт становив разючі 13%.
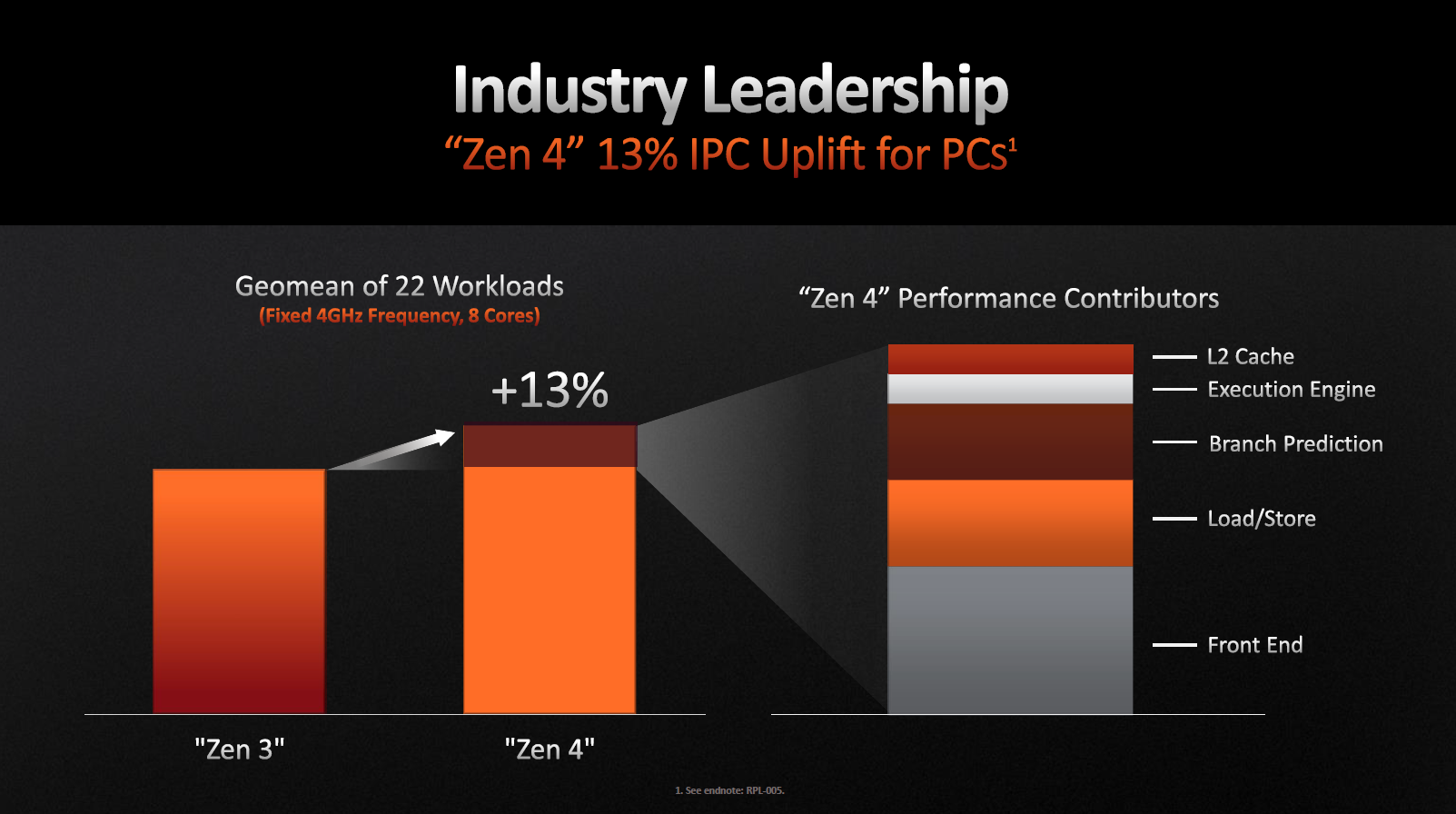
Заради інтересу розгляньмо відсоткове співвідношення для кожної архітектурної зміни:
- +1% за подвоєння кешу L2.
- +1% механізм виконання.
- +2,7% провісник розгалужень.
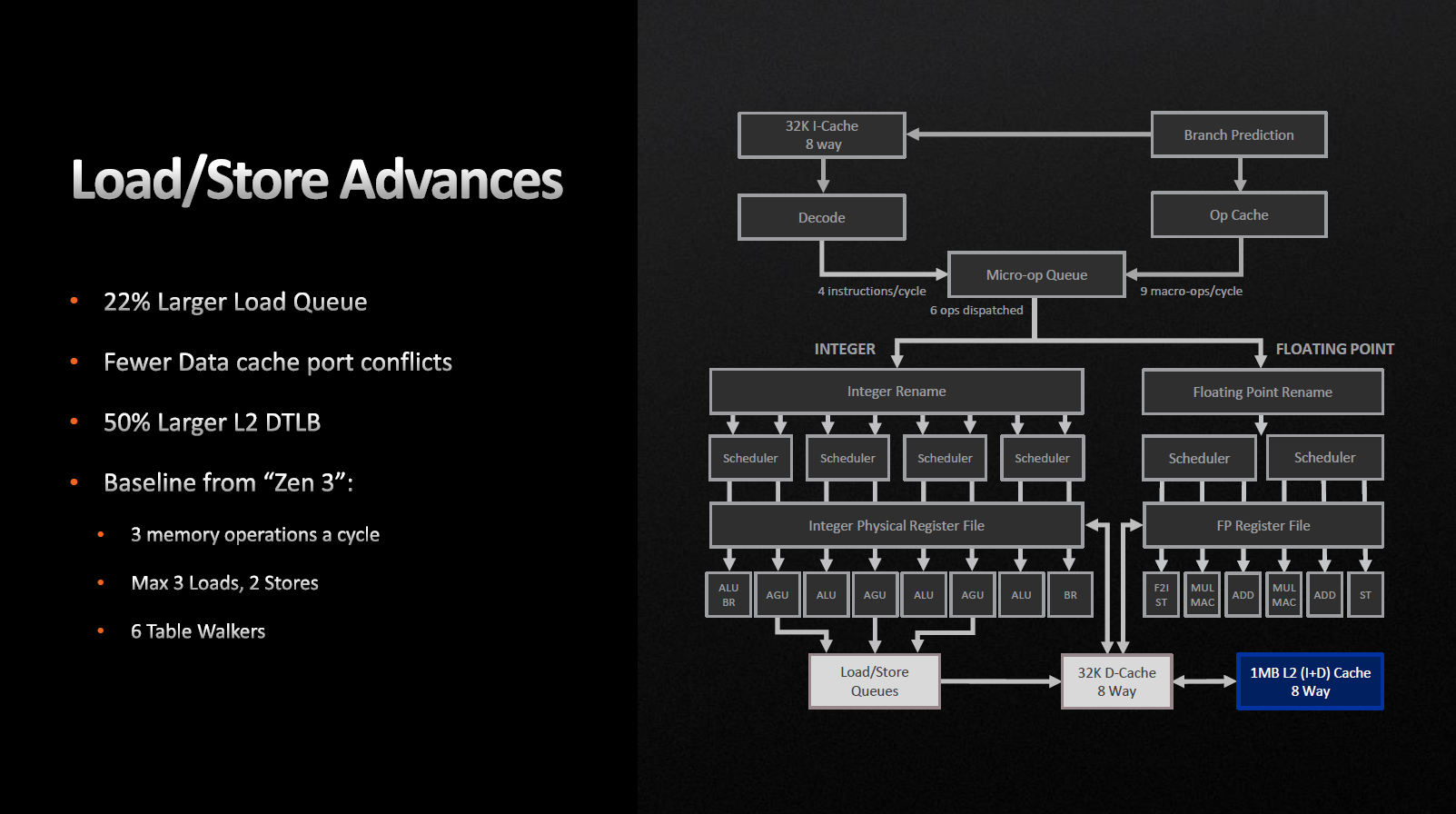
- +3% завантаження та зберігання даних.
- +5,2% покращення інтерфейсів.
Уважні користувачі можуть помітити, що поточний шлях AMD має схожість зі стратегією тік-так, яка раніше використовувалася у синьому таборі. Zen 4 — насамперед це робота над помилками та усунення «вузьких місць» архітектури Zen.
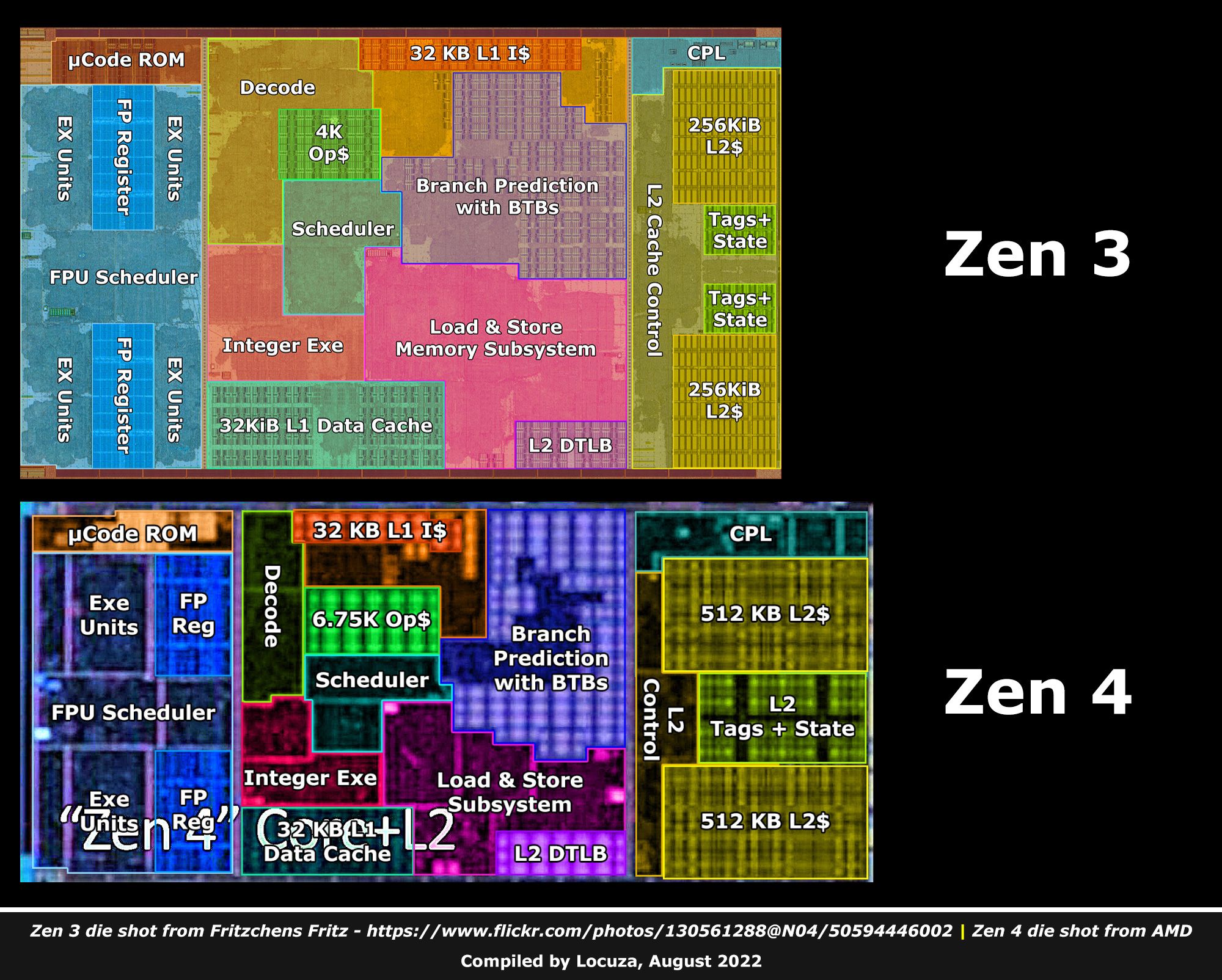
З кремнієвої точки зору компонування дещо змінилося, зокрема для FPU. Це четверта архітектура, яка змушує AMD у цьому блоці майже все переробляти. Якщо порівнювати з конкурентом, то він знайшов свою «золоту середину» майже 10 років тому і з того часу нічого кардинально не змінює.

Технологічний процес зробив серйозний крок уперед і тепер це довгоочікувані 5 нм. Усі процесори Zen 4 базуються на технологічному процесі під кодовою назвою N5 PPA від компанії TSMC. Він виробляється за другим поколінням технології EUV, яка є передовим рішенням у «ливарній» промисловості з найкращими показниками продуктивності, потужності та площі (PPA). Техпроцес N5 PPA забезпечує швидкість приблизно на 15% вище, ніж технологія N7, або зниження споживаної потужності приблизно на 30%. Щільність розміщення транзисторів при цьому зростає в 1,8 раза. Саме завдяки оновленому техпроцесу процесори Ryzen здатні підкорювати бар'єр 5 ГГц навіть у мультипотоковому навантаженні.
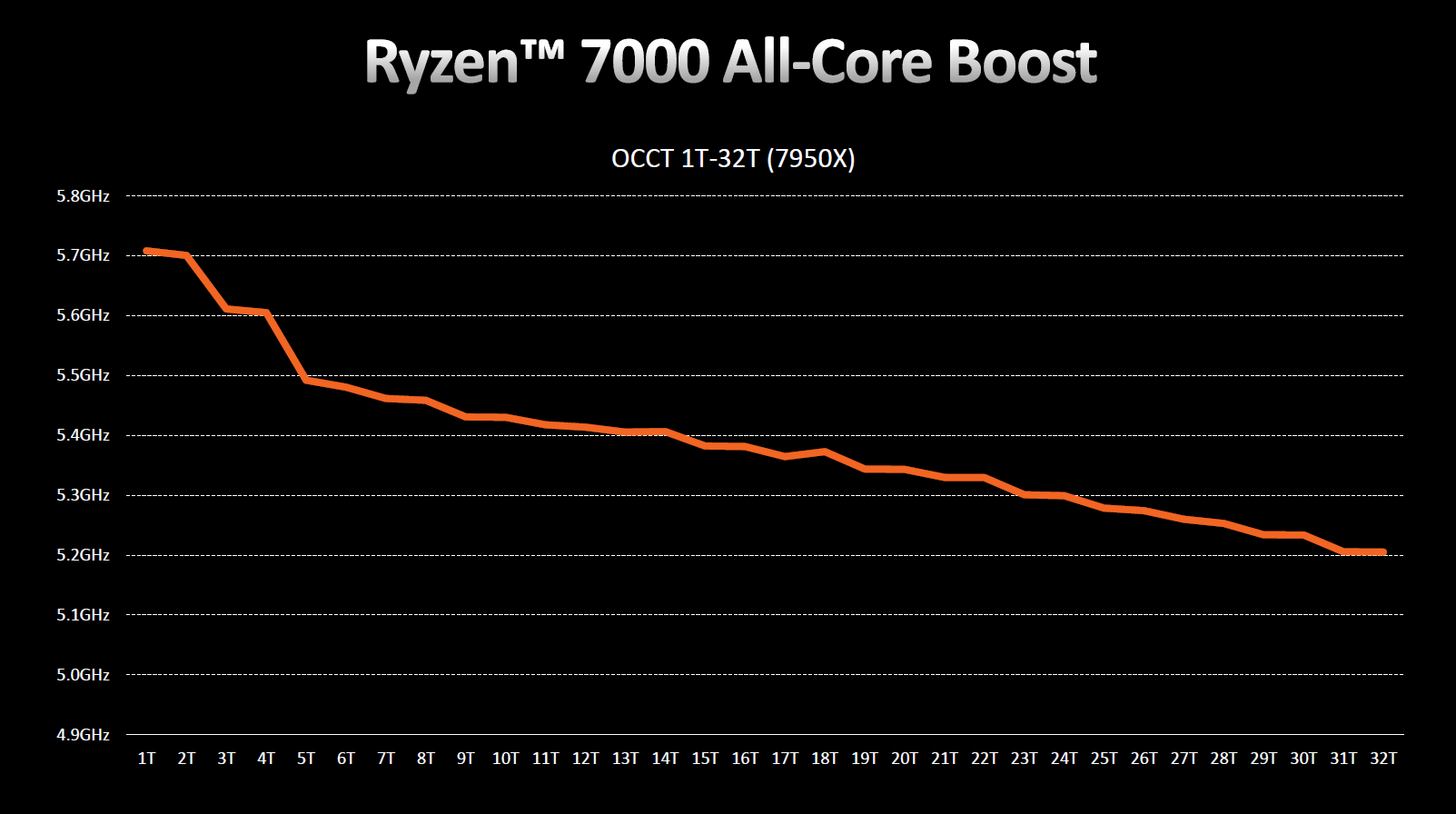
Інженери AMD не забули й про аматорів однопотокового навантаження. 5,7 ГГц з коробки та можливість покращити результат до разючих 5,85 ГГц після оптимізації вольт-частотної кривої. AMD заявляє про 29% приріст продуктивності в однопотоковому навантаженні щодо попередника. Попри те, що навіть програмне забезпечення управління RGB використовує кілька ядер, битва за цю міфічну корону триває.

Значний акцент приділено метрикам енергоефективності архітектур щодо техпроцесу. Zen 4 на 49% продуктивніше при тому ж енергоспоживанні щодо Zen 3 або на 62% вимагає менше енергії при ідентичній продуктивності.

Зворотний бік медалі? Так, він є. Перше, що зразу можна побачити, це рівень TDP, який зріс зі 105 до 170 Вт. Площа ядра, включаючи кеш-пам'ять L2, становить 3,84 мм², що приблизно на 18 % менше у порівнянні з площею близько 4,11 мм² у Zen 3 на 7-нм техпроцесі. Це означає, що тепловиділення зросло з 1,25 Вт/мм² до разючих 1,92 Вт на мм². Максимально допустима температура не змінилася, ті самі 95 °C. На противагу цьому, на жаль, не було вжито жодних дій (принаймні у документації для рецензентів). Припій на місці. Хотів би нагадати, що свого часу компанія Intel вже стикалася з проблемою перегріву і як рішення сточувала верхній шар кристала, щоб поліпшити теплові процеси між кристалом та теплорозподільною кришкою (IHS). Резюмуючи, можу сказати тільки одне — користувачам таки доведеться розщедритися на добротну систему охолодження, а любителям розгону взагалі перейти на кастомне водяне охолодження.
Будова CCD та ієрархія кешів
Ієрархія кешів має невеликі зміни.
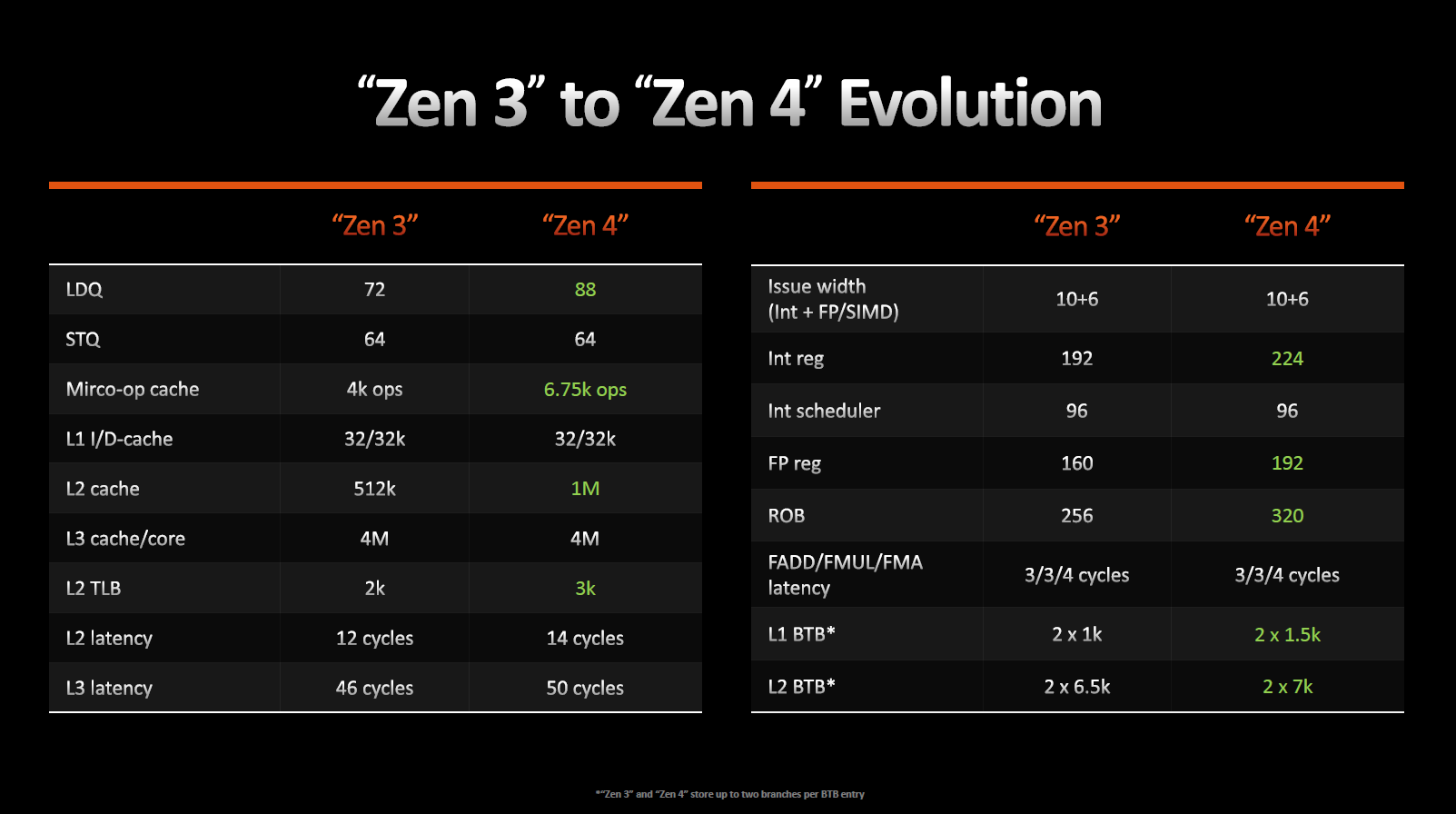
Кеш-пам'ять L1-I та L1-D, як і раніше, має 32 Кбайт з 8-канальною асоціативністю, а кеш-пам'ять другого рівня став 1024 Кбайт з 8-канальною асоціативністю, що вдвічі більше, ніж у попередника. З погляду транзисторного бюджету незрівнянне підвищення витрат щодо отриманого приросту IPC на 1%, але це виправдовує себе на високоінтенсивних навантаженнях, зокрема у серверному сегменті.
Zen 4 підтримує 64 суттєвих пропусків між L2 і L3 на ядро і 224 між L3 та оперативною пам'яттю.
Кеш інструкцій (L1-I) на цикл може забезпечувати 32-байтову вибірку, в той час, як кеш даних (L1-D) допускає три 32-байтових завантаження і два 32-байтових збереження за цикл. Черга на збереження не змінилася, але черга на завантаження зросла з 72 до 88. Буфер трансляції адрес (TLB) L2-кешу також виріс на 50% і тепер становить 3 Кбайт.
Варто зазначити, що подібні зміни мають серйозно вплинути на продуктивність у високоінтенсивних завданнях, які призводять до більшої кількості завантажень, ніж збереження.
Доступ прилеглих ядер до кешу L3 здійснюється без використання Infinity Fabric, тут змін немає. Затримка L3-кешу збільшилася з 46 до 50 тактів. Основною причиною цього явища так само є обсяг монолітної структури та зрослі тактові частоти L3. Механізм заповнення кешу третього рівня — віктимний, тобто на нього не поширюється попередня вибірка, дані просто витісняються до нього з L2. Таким чином, L3-кеш виявляється переважно ексклюзивним.
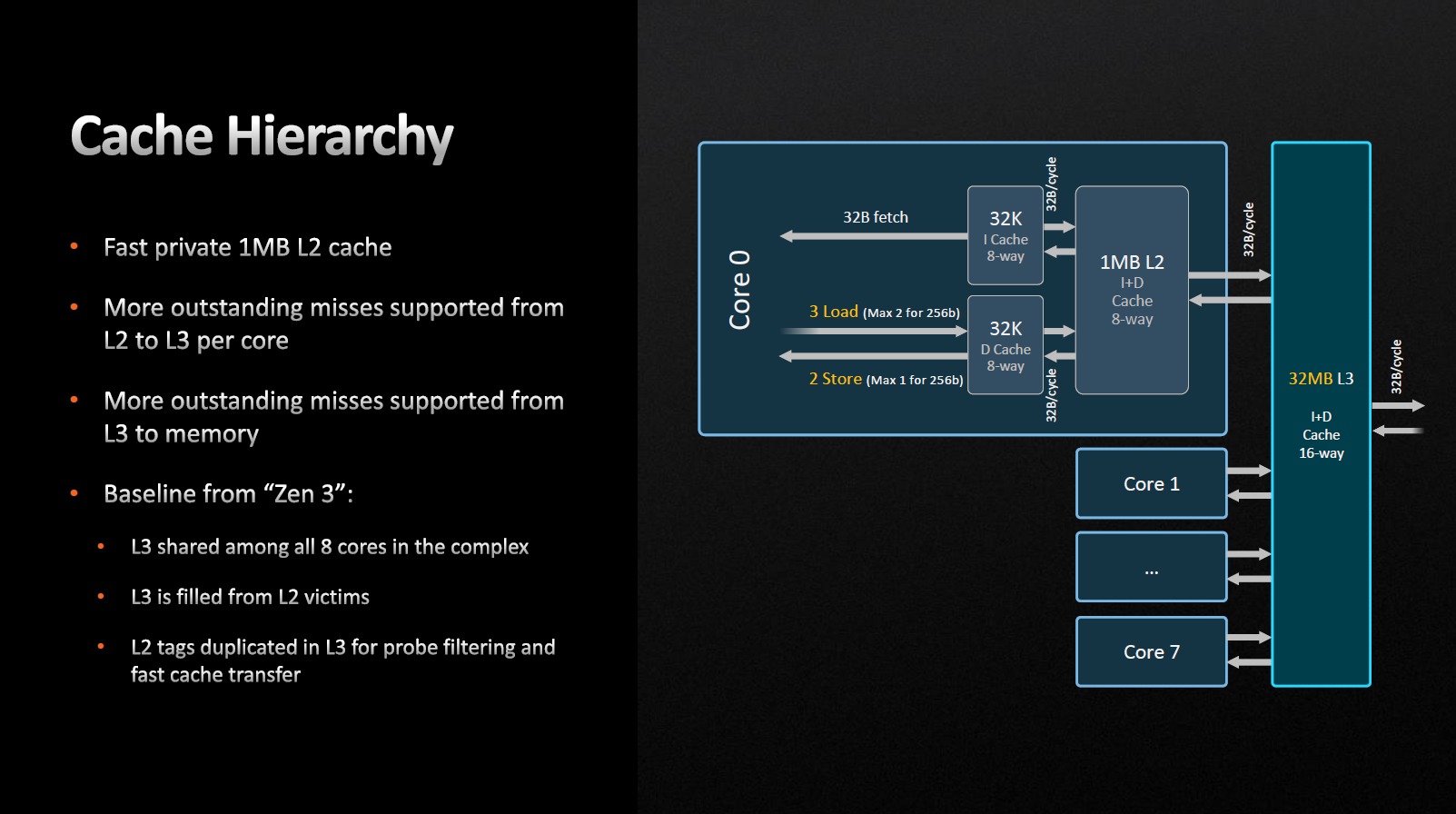
Компанія AMD заявляє, що кількість промахів кешів L2 до L3 та L3 до оперативної пам'яті зросла. Тобто якщо результат запиту, що обробляється, відсутній в кеші, і щоб його отримати необхідно звертатися до зовнішньої пам'яті. При отриманні відповіді ми можемо зберегти нове значення в кеш, витіснивши деяке старе, як результат — збільшення швидкодії.
Виконавчий блок та провісник розгалужень
Виконавчий блок майже не змінився. Так само ми маємо чотири цілочисельних уніфікованих планувальників та двох планувальників дійсних значень. Реєстровий файл загального призначення зріс зі 192 до 224, а регістровий файл для дійсних значень зріс зі 160 до 192 записів.
«Ширина» конвеєра залишилася незмінною, він дозволяє виконувати за один цикл 10 цілочисельних та шість мікрооперацій з дійсними числами.
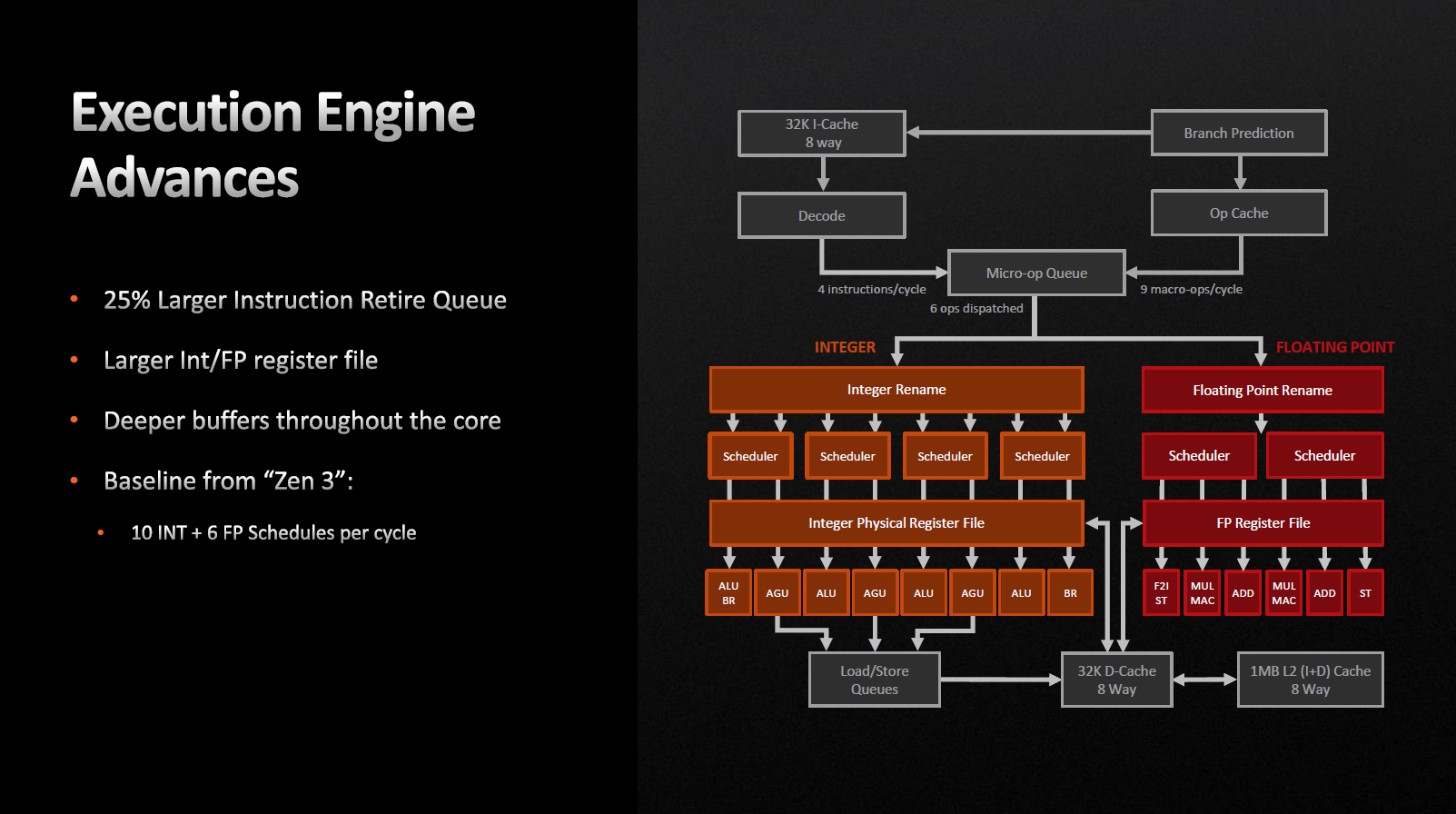
Зазначається, що буфери по всьому ядру стали глибшими, а черга команд на вибуття зросла на 25%.
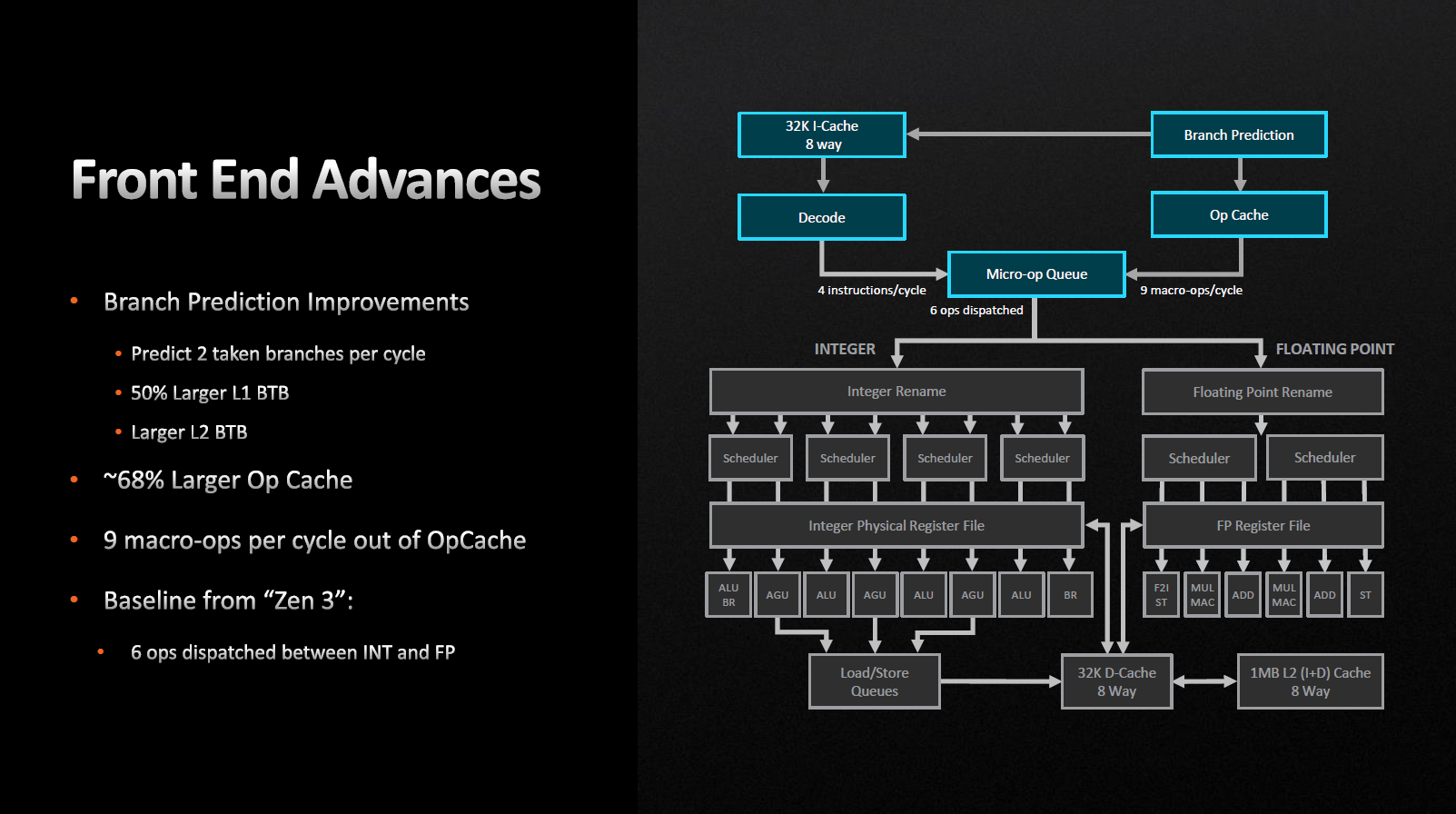
Архітектура Zen 4 дозволяє провіснику розгалужень за один цикл обробляти відразу дві «гілки» замість однієї, як було раніше. Принагідно були збільшені цільові буфери розгалуження (BTB) для кешів L1 і L2. Мікроопераційний кеш був також збільшений з 4 до 6,75 Кбайт. Як результат, ми можемо спостерігати збільшення кількості вихідних мікрооперацій з операційного кешу з восьми до дев'яти за один цикл.
Хочу зазначити, що всі вищезгадані зміни насамперед спрямовані на те, щоб конвеєр був максимально завантажений і не виникало ситуацій із «простоєм». Так, безумовно хотілося побачити «ширший» конвеєр і «жирніший» декодер інструкцій, але це припасовано для майбутніх архітектур.
AVX-512 та прискорення обчислень для нейромереж
Якось «батько» сімейства операційних систем Linux Лінус Торвальдс критично висловився про перспективи розширення набору команд Intel AVX-512 (Advanced Vector Extensions). Основним посилом було те, що на той момент Intel марно палила транзисторний бюджет, створюючи магічні інструкції, придатні тільки для тестів і порівняльної переваги над конкурентами. Закінчилося це тим, що Intel почала блокувати AVX-512 через виробників материнських плат. Тепер із цим прийшла компанія AMD. Чому?
Як і всі попередники, AVX-512 призначений прискорити роботу додатків, які використовують мультимедійні інструкції до роботи певних алгоритмів. Наприклад, AVX та AVX2 використовуються для прискорення конвертації відео, емуляторів ігрових приставок, роботи фото- та відеоредакторів, зокрема для розмиття фону та інших операцій.

Помітного прискорення коштом нових інструкцій вже сьогодні можна досягти й при кодуванні відео формату HEVC. Представники AMD говорять про те, що ці інструкції в першу чергу стануть у пригоді для програмного забезпечення, яке залучає глибинне навчання та штучний інтелект, а також різні техніки масштабування зображень.
Друга причина поточного приходу AVX-512 у настільний сегмент — це те, що серверна архітектура є батьком настільних процесорів. Саме в серверній архітектурі AVX-512 досить ефективно використовується для наукових розрахунків, моделювання та інших високоінтенсивних задач. По суті те, що ми маємо, це приємний бонус, на якому робиться акцент.
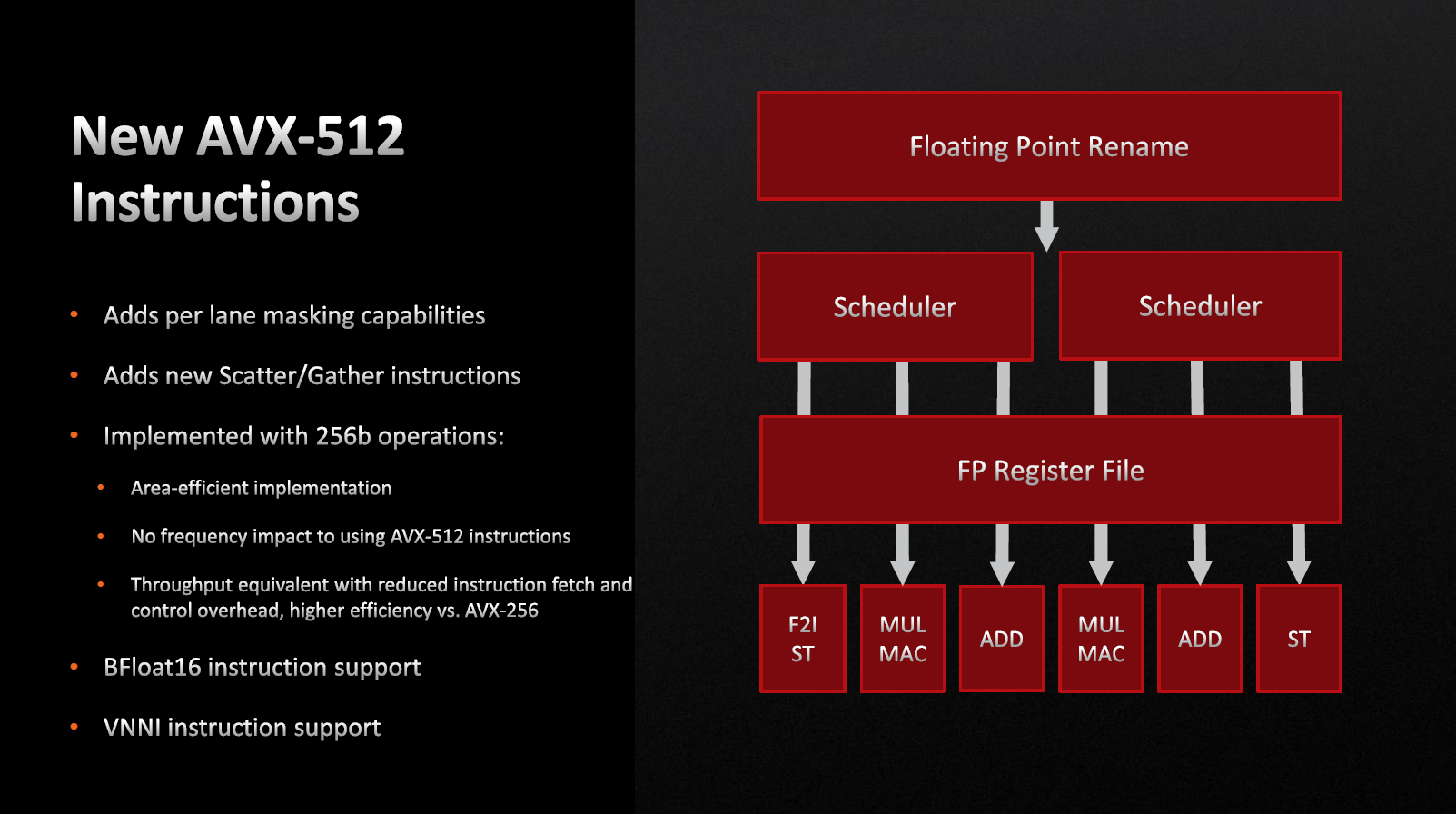
Потрібно віддати належне, штрафів виконання AVX-512 немає, а частотний ліміт обмежений лише допусками струму та температури.
IOD та iGPU
«Система на чипі», він же IOD зазнав серйозних змін — він виконаний за нормами 6 нм замість 12 нм, в нього було інтегровано відеоядро з архітектурою RDNA2, і він також отримав підтримку PCIe 5.0.

Завдяки вдосконаленому техпроцесу площа кристала не зросла, вона становить ті ж 125 мм² попри те, що було інтегровано графічне ядро.
Воно підтримує AV1-декодування, кодування та декодування H.264 й HEVC. Виведення зображення може здійснюватися через порти DisplayPort 2.0 (пропускна здатність 40 Гбіт/с) та HDMI 2.1 або через USB Type-C, який працює в режимі перехідника на DisplayPort.

IOD має такий саме модуль відео (VCN) і дисплея (DCN), що й Ryzen 6000. Попри те, що всі чипи Ryzen 7000 матимуть вбудовані iGPU, компанія, як і раніше, випускатиме APU Zen 4 з потужнішими iGPU. Оскільки у вбудованому графічному ядрі всього 2 CU (Compute Unit), які працюють на 2,2 ГГц, воно не претендує стати конкурентом для справжніх гібридних процесорів, хоча продуктивність рішення таки дозволить змагатися з продуктами, які містять iGPU рівня Vega 6. Це дуже приємний бонус для тих, хто не має потреби у графічному адаптері, а використовує систему суто для робочих завдань. Так само це сподобається тим, хто часто змінює відеокарти та іноді доводиться чекати новинку вже продавши свій поточний графічний адаптер.
Зазначається, що IOD має дуже високу енергоефективність, оскільки побудований за аналогічною методологією, що і передові мобільні рішення Ryzen 6000.

Контролер пам'яті був незначно вдосконалений і складається з двох спарованих контролерів, які відповідають кожен за свій канал, як це реалізовано в мобільних або настільних гібридних процесорах останніх поколінь. Це дозволяє досягати вищих робочих частот на рівні 3000 МГц, не винаходячи знову «колесо». Зрозуміло, компанія AMD про це не робила слайди, оскільки це досить неприємний момент, адже фанати очікують на більше. Як аргумент для захисту своєї «гіпотези» я можу навести факт того, що користувачу не доступне управління tREFI, той самий очікуваний параметр для пам'яті DDR5. Нагадаю, що його значення визначає часовий інтервал між усіма процедурами регенерації пам'яті. Без нього повноцінна оптимізація неможлива, вона залишилася на тому самому технічному рівні, що і в епоху DDR4.
Зберігся і «феномен» падіння швидкості запису на моделях процесорів з одним CCD, оскільки швидкість обміну інформацією між CCD та IOD для запису становить половину швидкості читання. Як я писав раніше в попередніх матеріалах, це не є проблемою, оскільки під час виконання більшості розрахунків процесором втричі домінує потреба у читанні, ніж у записі.

Цікавою особливістю Zen 4 є те, що Infinity Fabric (знайоме всім FCLK) було «відв'язане» від домену з контролером пам'яті, диких падінь продуктивності більше не передбачається при зміні частоти FCLK. Аналогічний підхід використовують і в архітектурі RDNA2. Це також означає, що збільшення FCLK позитивно позначиться на пропускній здатності та латентності між CCD. Рішення з одним CCD збільшення майже не відчують.
Компанія AMD заявляє, що Infinity Fabric було дещо оптимізовано, але прикладів не наводиться. Наважусь припустити, що йдеться про виправлення архітектурної проблеми покоління Zen 3. Полягала вона в тому, якщо FCLK досягала частоти понад 1800 МГц вона починала працювати в динамічному режимі, нерідко частотні піки досягали 2000+ МГц, що в користувачів, власне, і викликало WHEA. Це доведеться перевірити у майбутніх тестуваннях. На перших UEFI, які були доступні рецензентам, FCLK могла стабільно працювати до 2133 МГц включно, що буде за підсумком — завдання майбутніх матеріалів.
Що стосується «солодкої плями» для контролера пам'яті, на якому процесор сімейства Ryzen 7000 розкриє свій потенціал, то йдеться про 6000 МГц DDR5. Тобто максимальна частота UCLK може бути 3000 МГц. Перехід на вищу частоту призведе до переходу контролера пам'яті в режим 1:2, що негативно позначиться на латентності та продуктивності системи. Тому єдиною радістю користувачів буде модифікація таймінгів оперативної пам'яті або FCLK.
AMD EXPO
AMD EXPO — це вбудовані профілі розгону для пам'яті DDR5. Вони стали відповіддю на екстремальні профілі пам'яті Intel (XMP), які є невіддільною частиною багатьох комплектів DDR5. AMD EXPO вже протестовано і перевірено виробником на заводі, тому самостійно розбиратися в тонкощах тюнінгу таймінгів користувачеві не доведеться.
Профілів AMD EXPO у набору оперативної пам'яті може бути кілька і перемикання між ними можливе не тільки через UEFI, а ще через Ryzen Master в операційній системі. Це досить унікальна риса, оскільки XMP дозволяють перемикання робити лише через UEFI.

Компанія AMD обіцяє до 11% збільшення продуктивності відносного «сирих» налаштувань JEDEC з частотою в 5200 МГц.

Чогось надприродного в цьому немає, оскільки XMP здатний надати користувачеві аналогічні результати. Зрозуміло, можливий додатковий тюнінг користувача, який зможете подарувати ще до 10% продуктивності.

На момент старту продажів процесорів Ryzen 7000 буде доступно більш ніж 15 різних комплектів пам'яті від різних виробників і згодом це число зростатиме.
Що вибрати? Я хочу запропонувати таку схему підбору пам'яті — розділити робочу напругу на CL таймінг, чим нижче значення — тим цікавіший зразок для подальшого тюнінгу. Другий критерій — система охолодження пам'яті. Звертайте увагу на це і хто б що не говорив, пам'ять з тюнінгом — це гаряча штучка, адже температура негативно впливає на більш «ужаті» таймінги.
Безпека
Компанія AMD не забула і про клієнтську безпеку, представивши нові розширення та виправлення для віртуалізації та усунення спекулятивного виконання різних сценаріїв.

Попереднє тестування - Sandra 20/21
Сира математична продуктивність є однією з важливих метрик, з якою сьогодні я хочу вас познайомити.
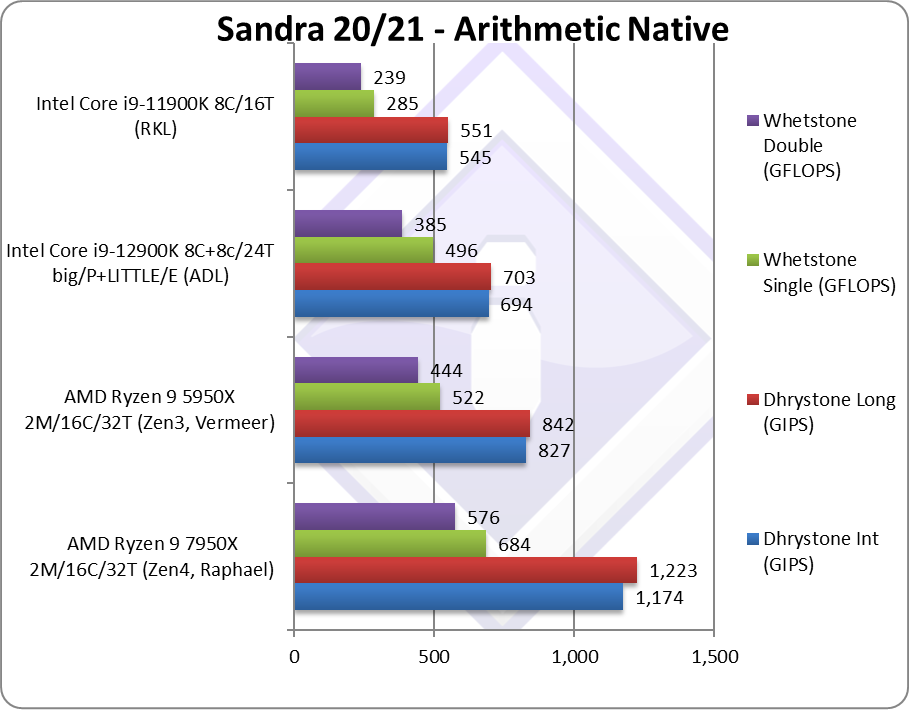
Результати Zen 4 стартують з неймовірних цифр: 42% швидше в цілісних обчисленнях і 30% швидше в обчисленнях з рухомою комою, але найголовніше, що це без використання AVX-512! Значно зрослі частоти та покращення ALU/FPU відіграли вирішальну роль. Конкурент в особі Intel Core-12900K просто залишається далеко позаду, тут і коментувати нема чого.

Навіть у векторизованих алгоритмах SIMD з важкими обчисленнями можна побачити ті самі результати: Zen 4 з AVX-512 на 60% швидше, ніж Zen 3, а в одному з тестів різниця становить 2,1 раза.

Обробка графічних зображень — це чудовий тест для оцінки можливостей AVX-512. У всіх тестах Zen 4 обходить попередника щонайменше у 2 рази, а в одному з тестів і зовсім різниця майже триразова.
Потрібно віддати належне, що оптимізація оперативної пам'яті у більшості сценаріїв здатна принести додаткову продуктивність.
Висновок
Процесори Ryzen 7000 серії, засновані на архітектурі Zen 4 і 5-нм техпроцесі здатні виправдати сміливі очікування найприскіпливіших користувачів.

Zen 4 — це безпрецедентний рівень продуктивності як в іграх, так і в робочих завданнях, при цьому ціна щодо попередника не зросла. Як бонус кожен користувач отримує ще й повноцінне інтегроване відеоядро, яке здатне працювати з найновішими стандартами кодування і виведення зображення на екран. На окрему похвалу заслуговує платформа AM5, яка зберігає сумісність із системами охолодження AM4, приносить підтримку DDR5 та стандарту PCI Express 5.0 з великою кількістю портів для підключення різноманітної периферії. План компанії AMD щодо життєвого циклу AM5 до 2025 року порадує користувачів, які не звикли змінювати материнську плату. Недоліки? Ціна на материнські плати та DDR5, у зв'язку з чим раджу користувачам ставитись до вибору, як до «власного весілля». На сьогодні все, а незабаром на вас чекає докладне тестування та матеріали, які дозволять вам отримати з цих процесорів ще більше продуктивності.