
З'явилися дані тестування прискорювачів штучного інтелекту AMD у новому наборі бенчмарків MLPerf Inference v4.1 від MLCommons. Цей тест симулює різні робочі навантаження, характерні для роботи з ШІ. За їх результатами, рішення AMD Instinct MI300X гідно конкурують з популярними прискорювачами Nvidia H100.

Протестовано серверні системи на базі нових процесорів AMD EPYC Turin, які використовують ядра на новій архітектурі Zen 5. Для оцінки продуктивності AMD представила результати прискорювачів Instinct MI300X, що працювали в складі системи Supermicro AS-8125GS-TNMR2. Графічні процесори працюють на відкритій програмній платформі AMD ROCm.
Бенчмарк здебільшого зосереджений на використанні моделі ШІ LLaMA2-70B із 70 мільярдами параметрів. Тести проведені в автономному режимі, який сфокусований на максимальній пропускній здатності токенів на секунду, та в серверних сценаріях, де імітуються запити в реальному часі з обмеженою затримкою.

Сервер із процесором EPYC 9374F Genoa і вісьмома прискорювачами Instinct MI300X показав результат 21028 токенів/сек у серверних сценаріях, що максимально близько до результату 21605 токенів/сек серверної системи Nvidia DGX100 із процесором Xeon. А система на базі нового процесора EPYC Turin показала найкращий результат у 22021 токенів/сек.
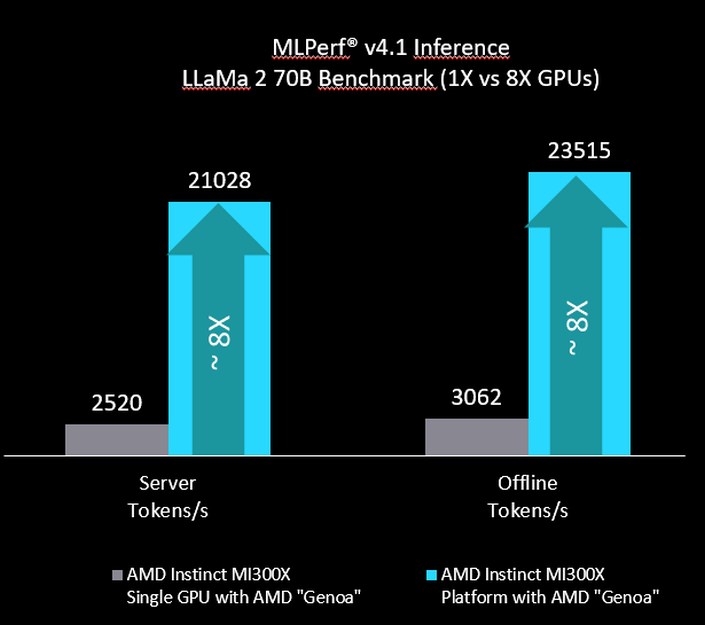
В офлайнових тестах Nvidia DGX100 утримує лідерство, хоча різниця з конфігурацією Turin + MI300X мінімальна. Це показує, що рішення AMD для ШІ не поступаються надпопулярним Nvidia H100.

Instinct MI300X використовує чип на архітектурі CDNA 3 та оснащується 192 ГБ пам'яті HBM3. Швидкісна шина Infinity Fabric дає змогу ефективно об'єднувати ці пристрої в обчислювальні кластери. AMD говорить про майже лінійне масштабування продуктивності при переході від одного прискорювача до восьми MI300X. Завдяки великому обсягу пам'яті платформа AMD має хороший потенціал для підтримки нових великих мовних моделей. Це вже сприяло партнерству AMD і Meta для підтримки LLaMa 3.1 405B.
Джерело:
TechPowerUp